言語処理100本ノック 2015 をすべてやりました
- 本家サイト: http://www.cl.ecei.tohoku.ac.jp/nlp100/
- 僕が書いたコード: https://github.com/r9y9/nlp100
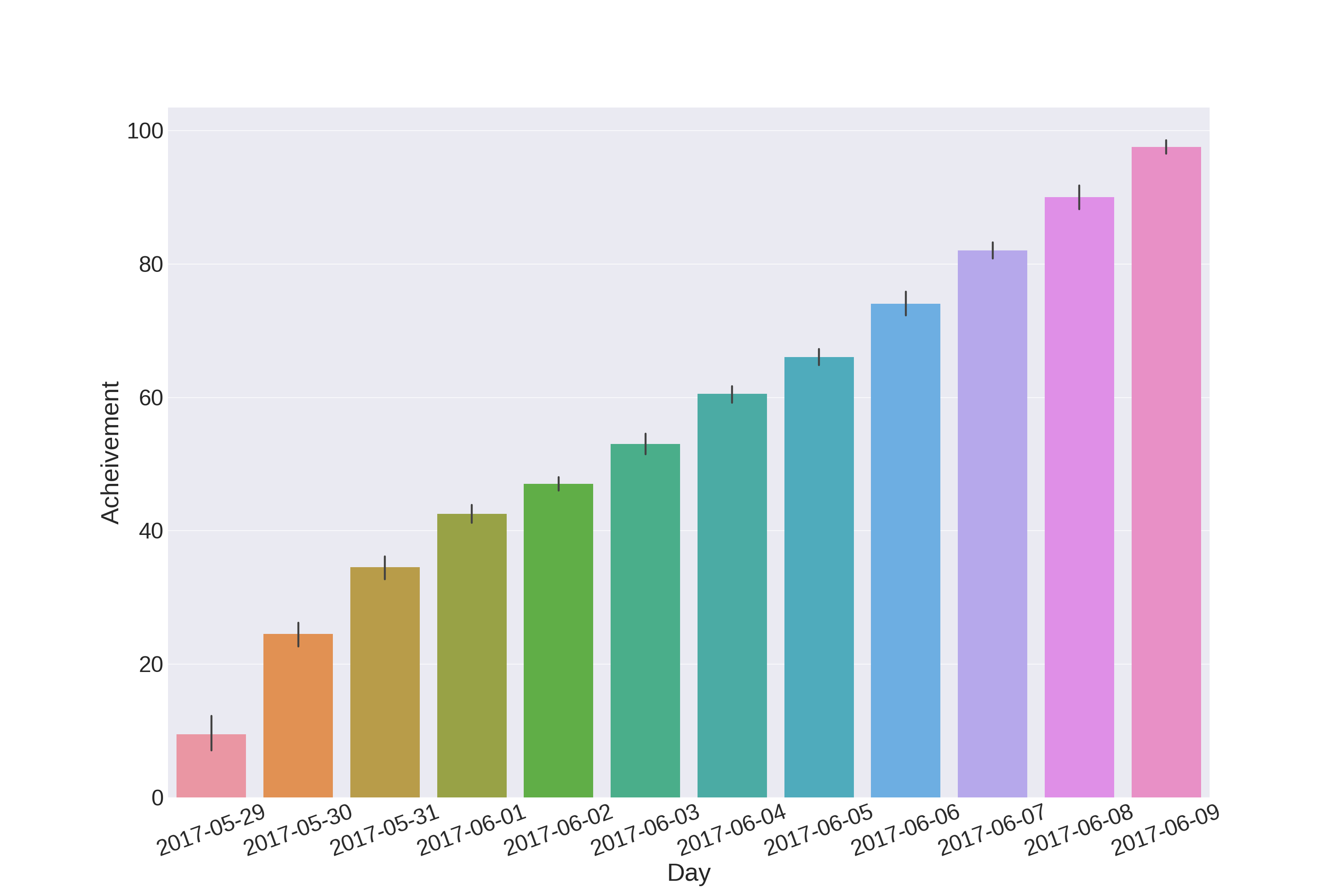
最近、自然言語処理(NLP)を勉強しようという熱が出ました。ある自然言語処理の問題を解きたかったのですが、 無知のためにか直感がまったく働かず、これはまずいと感じたので、 入門的なのに手を出そうと思った次第です。 結果、毎日やりつづけて、12日かかりました(上図は、横軸が日付、縦軸が達成した問題数です。図はseabornで適当に作りました)。 速度重視1で問題を解きましたが、思ったよりうまく進まず大変だった、というのが正直な感想です。以下、雑多な感想です。
- mecab, cabocha, CoreNLPの解析結果をパースするコードを書くのは、ただただ面倒に感じた
- NER実装しろ、みたいな問題があったらより楽しかったかなと思った
- 正規表現をまったく使いこなせていなかったことがわかったので、勉強し直せてよかった
- 全体を通して、第9章のword embeddingを自前で作る部分が一番楽しかった
- うろ覚えですが2、問題文中に表現が正確でない(と感じる)部分があって、困惑したことがあった
- 9割python、1割juliaで書きましたが、sklearn, numpy, scipyなどを使わなくてよい、かつ速度が重要な場合は、簡単に速くできるのでjulia良い
- python、ライブラリが充実しすぎていて本当に楽
- 素人の言語処理100本ノック:まとめ - Qiita がとても丁寧で、解いたはいいものの自信がないときなどに、ちょくちょく見ていました。参考になりました
今後
深層学習による自然言語処理を買ったので3、それを読んで、自然言語処理の勉強を続けようと思います。
Ryuichi Yamamoto
Engineer/Researcher
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.