【声質変換編】Statistical Parametric Speech Synthesis Incorporating Generative Adversarial Networks [arXiv:1709.08041]
10/11 追記: IEEE TASLPのペーパー (Open access) が公開されたようなので、リンクを貼っておきます: https://ieeexplore.ieee.org/document/8063435/
arXiv論文リンク: arXiv:1709.08041
2017年9月末に、表題の 論文 が公開されたのと、nnmnkwii という designed for easy and fast prototyping を目指すライブラリを作ったのもあるので、実装してみました。僕が実験した限りでは、声質変換 (Voice conversion; VC) では安定して良くなりました(音声合成ではまだ実験中です)。この記事では、声質変換について僕が実験した結果をまとめようと思います。音声合成については、また後日まとめます
- コードはこちら: r9y9/gantts | PyTorch implementation of GAN-based text-to-speech and voice conversion (VC) (TTSのコードも一緒です)
- 音声サンプルを聴きたい方はこちら: The effects of adversarial training in voice conversion | nbviewer (※解説はまったくありませんのであしからず)
なお、厳密に同じ結果を再現しようとは思っていません。同様のアイデアを試す、といったことに主眼を置いています。コードに関しては、ここに貼った結果を再現できるように気をつけました。
概要
一言でいえば、音響モデルの学習に Generative Adversarial Net (GAN) を導入する、といったものです。少し具体的には、
- 音響モデル(生成モデル)が生成した音響特徴量を偽物か本物かを見分けようとする識別モデルと、
- 生成誤差を小さくしつつ (Minimum Generation Error loss; MGE loss の最小化) 、生成した特徴量を識別モデルに本物だと誤認識させようとする (Adversarial loss; ADV loss の最小化) 生成モデル
を交互に学習することで、自然音声の特徴量と生成した特徴量の分布を近づけるような、より良い音響モデルを獲得する、といった方法です。
ベースライン
ベースラインとしては、 MGE training が挙げられています。DNN音声合成でよくあるロス関数として、音響特徴量 (静的特徴量 + 動的特徴量) に対する Mean Squared Error (MSE loss) というものがあります。これは、特徴量の各次元毎に誤差に正規分布を考えて、その対数尤度を最大化することを意味します。 しかし、
- 静的特徴量と動的特徴量の間には本来 deterministic な関係があることが無視されていること
- ロスがフレーム単位で計算されるので、 (動的特徴量が含まれているとはいえ) 時間構造が無視されてしまっていること
から、それらの問題を解決するために、系列単位で、かつパラメータ生成後の静的特徴量の領域でロスを計算する方法、MGE training が提案されています。1
実験
実験条件
CMU ARCTIC から、話者 clb と slt のwavデータそれぞれ500発話を用います。439を学習用、56を評価用、残り5をテスト用にします。音響特徴量には、WORLDを使って59次のメルケプストラムを抽出し、0次を除く59次元のベクトルを各フレーム毎の特徴量とします。F0、非周期性指標に関しては、元話者のものをそのまま使い、差分スペクトル法を用いて波形合成を行いました。F0の変換はしていません。音響モデルには、
で述べられている highway network を用います。ただし、活性化関数をReLUからLeakyReLUにしたり、Dropoutを入れたり、アーキテクチャは微妙に変えています。前者は、調べたら勾配が消えにくくて学習の不安定なGANに良いと書いてある記事があったので(ちゃんと理解しておらず安直ですが、実験したところ悪影響はなさそうでしたので様子見)、後者は、GANの学習の安定化につながった気がします(少なくともTTSでは)。Discriminatorには、Dropout付きの多層ニューラルネットを使いました。MGE loss と ADV loss をバランスする重み w_d は、 1.0 にしました。層の数、ニューロンの数等、その他詳細が知りたい方は、コードを参照してください。実験に使用したコードの正確なバージョンは ccbb51b です。ハイパーパラメータは こちら です。
ここで示す結果を再現したい場合は、
- コードをチェックアウト
- パッケージと依存関係をインストール
clbとsltのデータをダウンロード(僕の場合は、~/data/cmu_arcticにあります
そして、以下のスクリプトを実行すればOKです。
./vc_demo.sh ~/data/cmu_arctic
なお実行には、GPUメモリが4GBくらいは必要です(バッチサイズ32の場合)。GTX 1080Ti + i7-7700K の計算環境で、約1時間半くらいで終わります。スクリプト実行が完了すれば、generated ディレクトリに、ベースライン/GAN それぞれで変換した音声が出力されます。以下に順に示す図については、デモノートブック を実行すると作ることができます。
変換音声の比較
テストセットの5つのデータに対しての変換音声、およびその元音声、ターゲット音声を比較できるように貼っておきます。下記の順番です。
- 元話者の音声
- ターゲット話者の音声
- MGE Loss を最小化して得られたモデルによる変換音声
- MGE loss + ADV loss を最小化して得られたモデルによる変換音声
比較しやすいように、音量はsoxで正規化しました。
arctic_a0496
arctic_a0497
arctic_a0498
arctic_a0499
arctic_a0500
clb, slt は違いがわかりにくいと以前誰かから指摘されたのですが、これに慣れてしまいました。わかりづらかったらすいません。僕の耳では、明瞭性が上がって、良くなっているように思います。
Global variance は補償されているのか?
統計ベースの手法では、変換音声の Global variance (GV) が落ちてしまい、品質が劣化してしまう問題がよく知られています。GANベースの手法によって、この問題に対処できているのかどうか、実際に確認しました。以下に、データセット中の一サンプルを適当にピックアップして、GVを計算したものを示します。縦軸は対数、横軸はメルケプストラムの次元です。
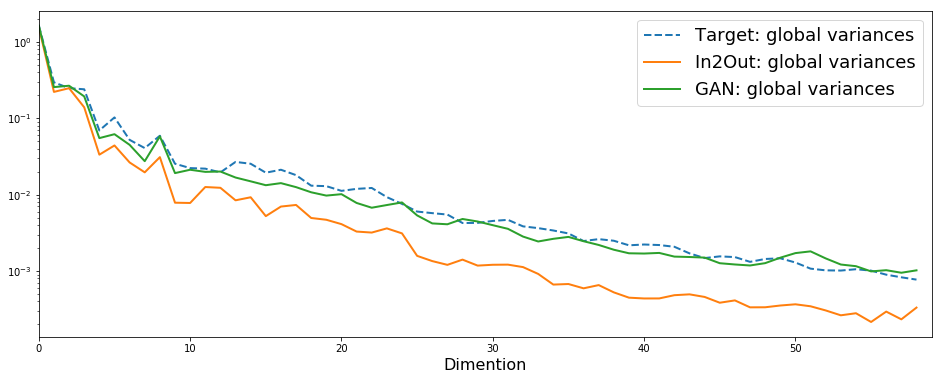
おおおまか、論文で示されているのと同等の結果を得ることができました。
Modulation spectrum (変調スペクトル) は補償されているのか?
GVをより一般化ものとして、変調スペクトルという概念があります。端的に言えば、パラメータ系列の時間方向に対する離散フーリエ変換の二乗(の対数※定義によるかもですが、ここでは対数をとったもの)です。統計処理によって劣化した変換音声は、変調スペクトルが自然音声と比べて小さくなっていることが知られています。というわけで、GANベースの方法によって、変調スペクトルは補償されているのか?ということを調べてみました。これは、論文には書いていません(が、きっとされていると思います)。以下に、評価用の音声56発話それぞれで変調スペクトルを計算し、それらの平均を取り、適当な特徴量の次元をピックアップしたものを示します。横軸は変調周波数です。一番右端が50Hzです。
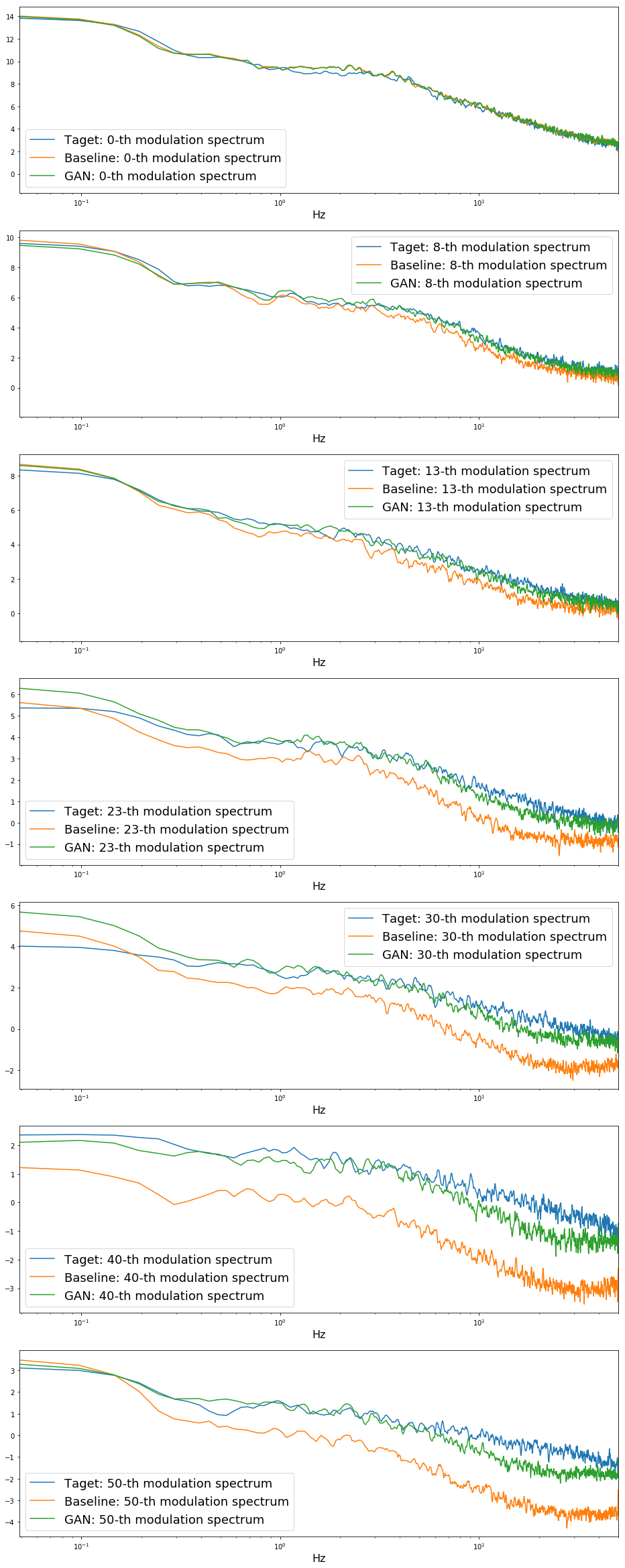
特に高次元の変調スペクトルに対して、ベースラインは大きく落ちている一方で、GANベースでは比較的自然音声と近いことがわかります。しかし、高次元になるほど、自然音声とGANベースでも違いが出ているのがわかります。改善の余地はありそうですね。
特徴量の分布
論文で示されているscatter plotですが、同じことをやってみました。
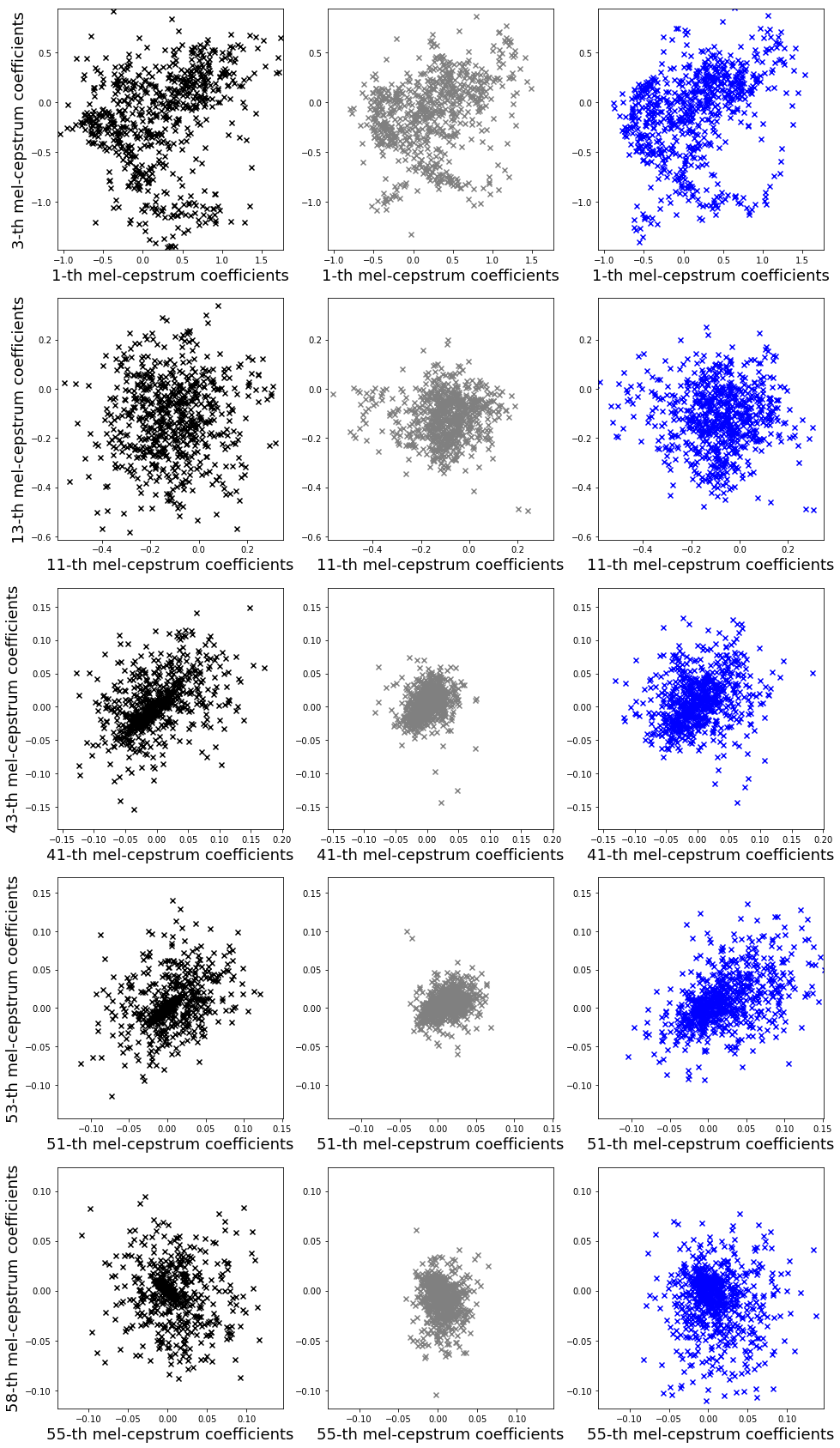
概ね、論文通りの結果となっています。
詐称率について
w_d を変化させて、詐称率がどうなるかは実験していないのですが、w_d = 1.0 の場合に、だいたい0.7 ~ 0.9 くらいに収まることを確認しました。TTSでは0.99くらいの、論文と同様の結果が出ました。くらい、というのは、どのくらい Discriminator を学習させるか、初期化としてのMGE学習(例えば25epochくらい)のあと生成された特徴量に対して学習させるのか、それとも初期化とは別でベースライン用のモデル(100epochとか)を使って生成された特徴量に対して学習させるのか、によって変わってくるのと、その辺りが論文からではあまりわからなかったのと、学習率や最適化アルゴリズムやデータによっても変わってくるのと、詐称率の計算は品質にはまったく関係ないのもあって、あまり真面目にやっていません。すいません
感想
- 効果は劇的、明らかに良くなりました。素晴らしいですね
- 論文で書かれている反復回数 (25epochとか)よりも、100, 200と多く学習させる方がよかったです(知覚的な差は微妙ですが)ロスは下がり続けていました。
- 実装はそんなに大変ではなかったですが、GANの学習が難しい感じがしました(VCではあまり失敗しないが、TTSではよく失敗する。落とし所を探し中
- Adam は学習は速いが、過学習ししやすい。GANも不安定になりがちな気がしました
- Adagrad は収束は遅いが、安定
- MGE loss と ADV loss の重みの計算は、適当にclipするようにしました。しなくてもだいたい収束しますが、バグがあると簡単に発散しますね〜haha
- gradient clipping をいれました。TTSでは少なくとも良くなった気がします。VCはなしでも安定しているようです。
まとめ
とても良くなりました。素晴らしいです。今回もWORLDにお世話になりました。続いて、TTSでも実験を進めていきます。
GANシリーズのその他記事へのリンクは以下の通りです。
参考
Arxivにあるペーパーだけでなく、その他いろいろ参考にしました。ありがとうございます。
- Yuki Saito, Shinnosuke Takamichi, Hiroshi Saruwatari, “Statistical Parametric Speech Synthesis Incorporating Generative Adversarial Networks”, arXiv:1709.08041 [cs.SD], Sep. 2017
- Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari, “Training algorithm to deceive anti-spoofing verification for DNN-based text-to-speech synthesis,” IPSJ SIG Technical Report, 2017-SLP-115, no. 1, pp. 1-6, Feb., 2017. (in Japanese)
- Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari, “Voice conversion using input-to-output highway networks,” IEICE Transactions on Information and Systems, Vol.E100-D, No.8, pp.1925–1928, Aug. 2017
- https://www.slideshare.net/ShinnosukeTakamichi/dnnantispoofing
- https://www.slideshare.net/YukiSaito8/Saito2017icassp
- https://github.com/SythonUK/whisperVC
- Kobayashi, Kazuhiro, et al. “Statistical Singing Voice Conversion with Direct Waveform Modification based on the Spectrum Differential.” Fifteenth Annual Conference of the International Speech Communication Association. 2014.
-
論文では有効性が示されていますが、僕が試した範囲内で、かつ僕の耳にによれば、あまり大きな改善は確認できていません。客観的な評価は、そのうちする予定です。 ↩︎
Ryuichi Yamamoto
Engineer/Researcher
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.