【単一話者編】Deep Voice 3: 2000-Speaker Neural Text-to-Speech / arXiv:1710.07654 [cs.SD]
Summary
三行まとめ
- arXiv:1710.07654: Deep Voice 3: 2000-Speaker Neural Text-to-Speech を読んで、単一話者の場合のモデルを実装しました(複数話者の場合は、今実験中です (deepvoice3_pytorch/#6)
- arXiv:1710.08969 と同じく、RNNではなくCNNを使うのが肝です
- 例によって LJSpeech Dataset を使って、英語TTSモデルを作りました(学習時間半日くらい)。論文に記載のハイパーパラメータでは良い結果が得られなかったのですが、arXiv:1710.08969 のアイデアをいくつか借りることで、良い結果を得ることができました。
概要
Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention. [arXiv:1710.08969] で紹介した方法と、モチベーション、基本的な方法論はまったく同じのため省略します。モデルのアーキテクチャが異なりますが、その点についても前回述べたので、そちらを参照ください。 今回の記事では、DeepVoice3のアーキテクチャをベースにした方法での実験結果をまとめます。
予備実験
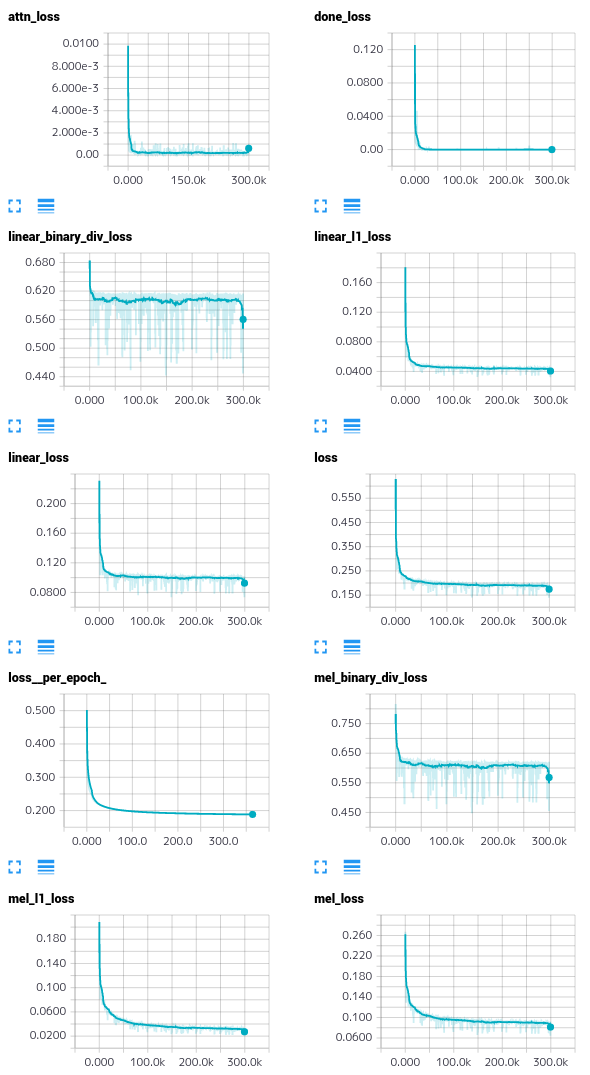
はじめに、可能な限り論文に忠実に、論文に記載のモデルアーキテクチャ、ハイパーパラメータで、レイヤー数やConvレイヤーのカーネル数を若干増やしたモデルで試しました。(増やさないと、LJSpeechではイントネーションが怪しい音声が生成されてしまいました)。しかし、どうもビブラートがかかったような音声が生成される傾向にありました。色々試行錯誤して改良したのですが、詳細は後述するとして、改良前/改良後の音声サンプルを以下に示します。
Generative adversarial network or variational auto-encoder.
(59 chars, 7 words)
改良前:
改良後:
いかがでしょうか。結構違いますよね。なお、改良前のモデルは53万イテレーション、改良後は21万イテレーション学習しました。回数を増やせばいいというものではないようです(当たり前ですが)。結論からいうと、モデルの自由度が足りなかったのが品質が向上しにくかった原因ではないかと考えています。
2017/12/21 追記:すいません、21万イテレーションのモデルは、何かしら別の事前学習したモデルから、さらに学習したような気がしてきました…。ただ、合計で53万もイテレーションしていないのは間違いないと思います申し訳ございません
実験
前回と同じく LJSpeech Dataset を使って、11時間くらい(21万ステップ)学習しました。モデルは、DeepVoice3で提案されているものを少しいじりました。どのような変更をしたのか、以下にまとめます。
- Encoder: レイヤー数を増やし、チャンネル数を大きくしました。代わりにカーネル数は7から3に減らしました
- Decoder: メル周波数スペクトログラムの複数フレームをDecoderの1-stepで予測するのではなく、arXiv:1710.08969 で述べられているように、1-stepで(粗い)1フレームを予測して、ConvTransposed1d により元の時間解像度までアップサンプリングする(要は時間方向のアップサンプリングをモデルで学習する)ようにしました
- Decoder: アテンションの前に、いくつかConv1d + ReLUを足しました
- Converter: ConvTransposed1dを二つ入れて、時間解像度を4倍にアップサンプリングするようにしました
- Converter: チャンネル数を大きくしました
- Decoder/Converter: レイヤーの最後にSigmoidを追加しました
- Loss: Guided attention lossを加えました
- Loss: Binary divergenceを加えました
- 共通: Linearを1x1 convolutionに変えました。Dilationを大きくとりました
上記変更点について、本来ならば、Extensiveに実験して、どれがどの程度有効か調べるのが一番良いのですが、計算資源の都合により、部分的にしかやっていません(すいません)。部分的とはいえ、わかったことは最後にまとめておきます。
計算速度は、バッチサイズ16で、5.3 step/sec くらいの計算速度でした。arXiv:1710.08969 よりは若干速いくらいです。GPUメモリの使用量は5 ~ 6GB程度でした。PyTorch v0.3.0を使いました。
学習に使用したコマンドは以下です。
python train.py --checkpoint-dir=checkpoints_deepvoice3 \
--hparams="use_preset=True,builder=deepvoice3" \
--log-event-path=log/deepvoice3_preset
コードのコミットハッシュは 7bcf1d0704 です。正確なハイパーパラメータが知りたい場合は、ここから辿れると思います。
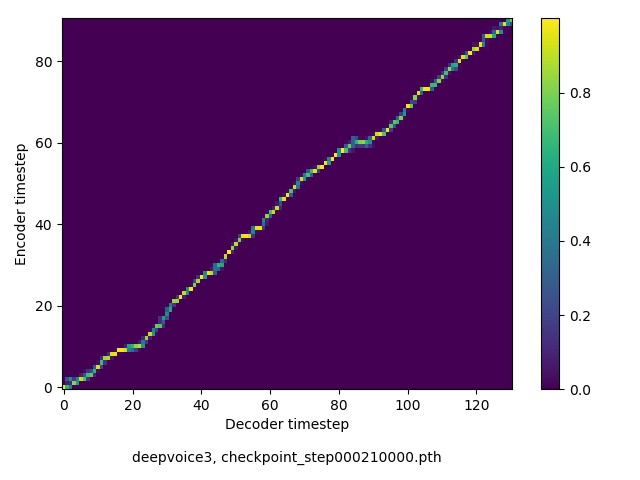
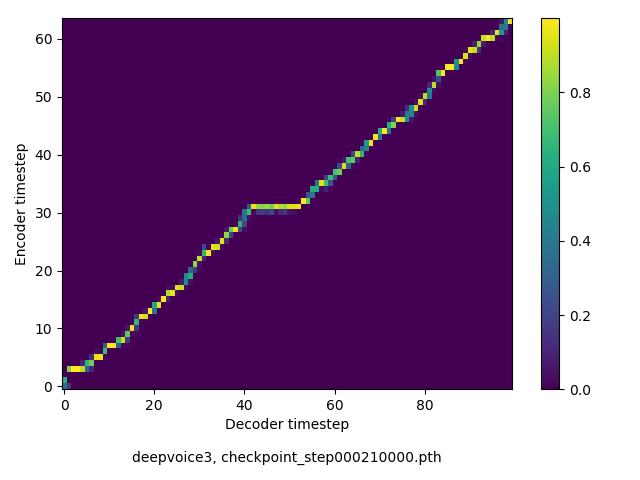
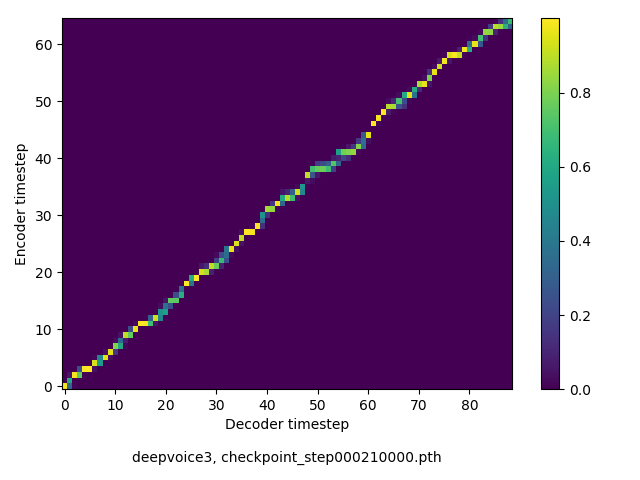
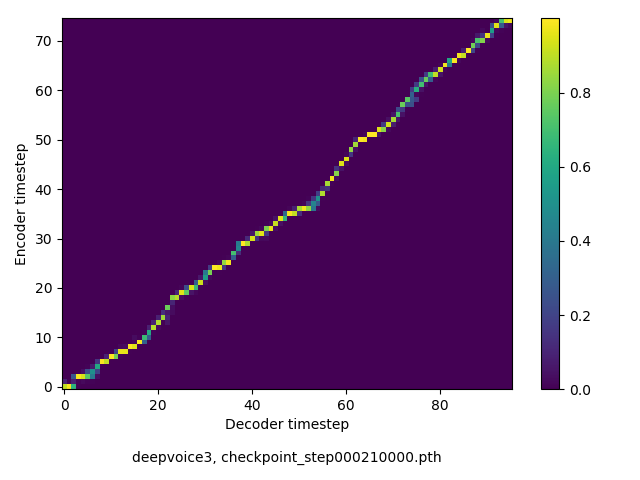
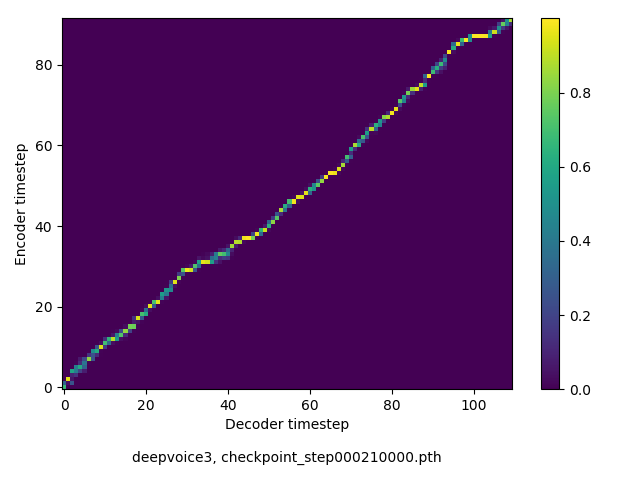
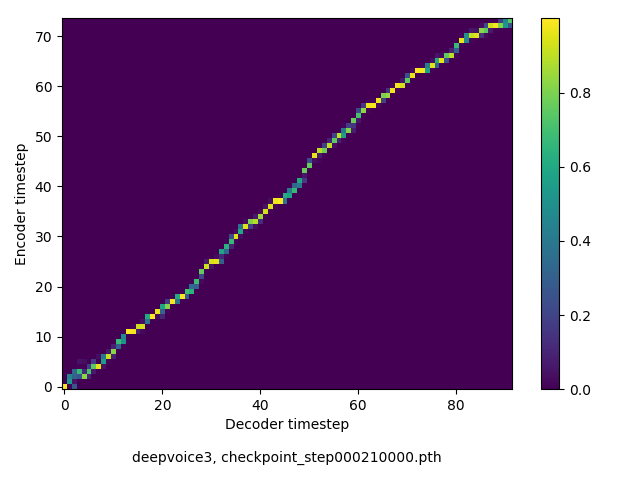
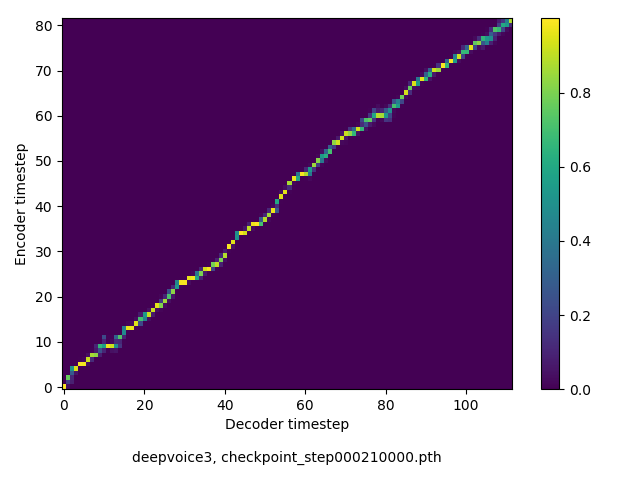
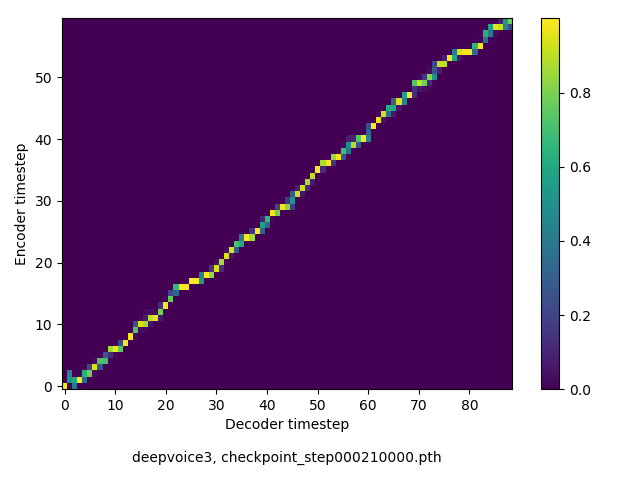
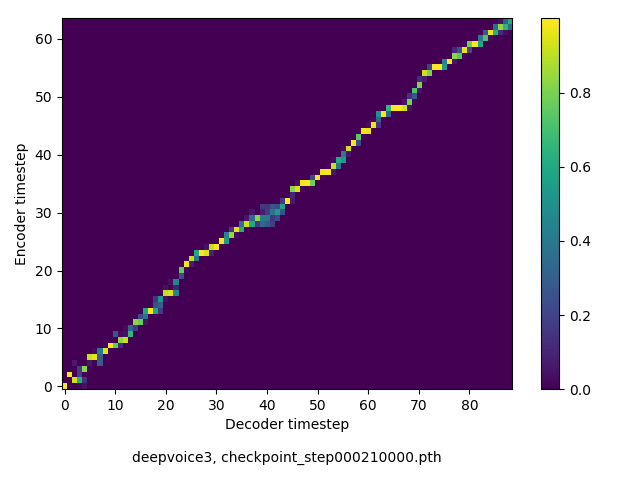
アライメントの学習過程
今回の実験ではアテンションレイヤーは二つ(最初と最後)ありますが、以下に平均を取ったものを示します。
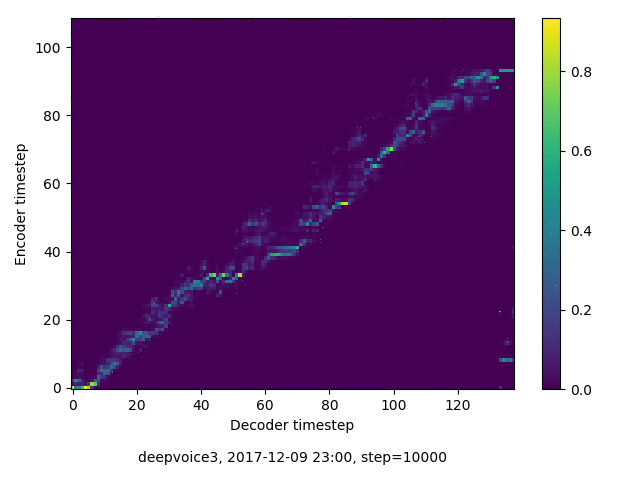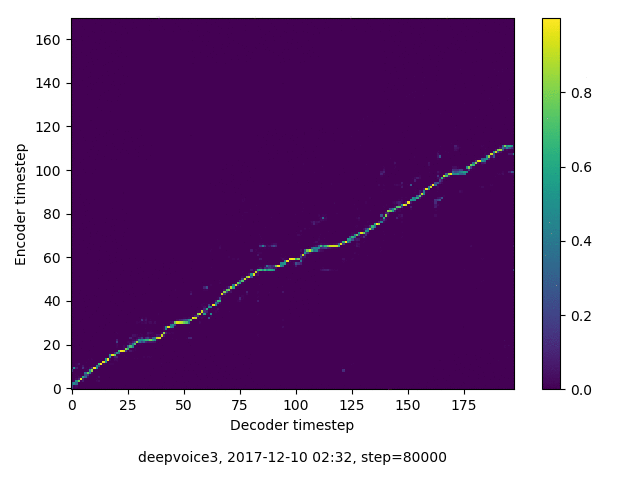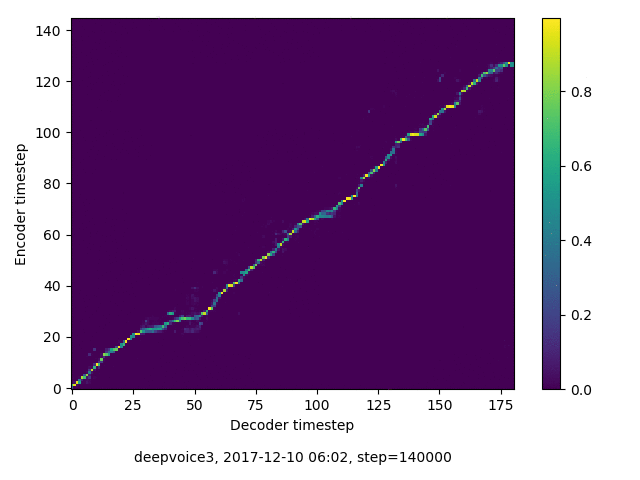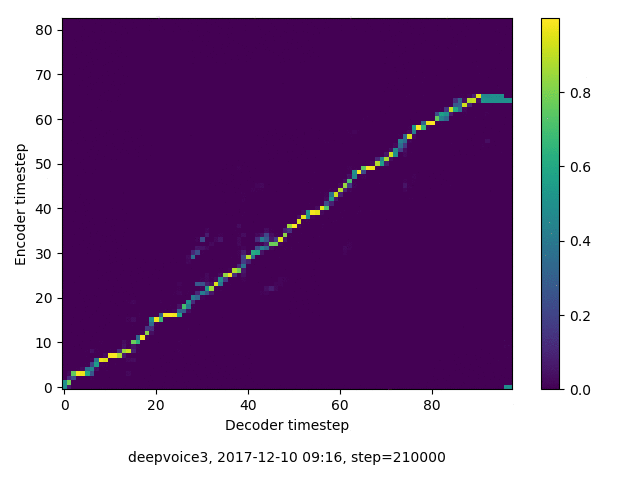
各種ロスの遷移
音声サンプル
前回の記事 で貼ったサンプルとまったく同じ文章を用いました。興味のある方は聴き比べてみてください。
https://tachi-hi.github.io/tts_samples/ より
icassp stands for the international conference on acoustics, speech and signal processing.
(90 chars, 14 words)
a matrix is positive definite, if all eigenvalues are positive.
(63 chars, 12 words)
a spectrogram is obtained by applying es-tee-ef-tee to a signal.
(64 chars, 11 words)
keithito/tacotron のサンプル と同じ文章
Scientists at the CERN laboratory say they have discovered a new particle.
(74 chars, 13 words)
There’s a way to measure the acute emotional intelligence that has never gone out of style.
(91 chars, 18 words)
President Trump met with other leaders at the Group of 20 conference.
(69 chars, 13 words)
The Senate’s bill to repeal and replace the Affordable Care Act is now imperiled.
(81 chars, 16 words)
Generative adversarial network or variational auto-encoder.
(59 chars, 7 words)
The buses aren’t the problem, they actually provide a solution.
(63 chars, 13 words)
まとめ
以下、知見をまとめますが、あくまでその傾向がある、という程度に受け止めてください。
- Tacotron, DeepVoice3で述べられているようにメル周波数スペクトログラムの複数フレームをDecoderの1-stepで予測するよりも、arXiv:1710.08969 で述べられているように、1-stepで(粗い)1フレームを予測して、ConvTransposed1d により元の時間解像度までアップサンプリングする方が良い。生成された音声のビブラートのような現象が緩和されるように感じた
- Dilationを大きくしても、大きな品質の変化はないように感じた
- Guided-attentionは、アテンションが早くmonotonicになるという意味で良い。ただし、品質に大きな影響はなさそうに感じた
- Encoderのレイヤー数を大きくするのは効果あり
- Converterのチャンネル数を大きくするのは効果あり
- Binary divergence lossは、学習を安定させるために、DeepVoice3風のアーキテクチャでも有効だった
- Encoder/Converterは arXiv:1710.08969 のものを、DecoderはDeepVoice3のものを、というパターンで試したことがありますが、arXiv:1710.08969に比べて若干品質が落ちたように感じたものの、ほぼ同等と言えるような品質が得られました。arXiv:1710.08969 ではDecoderに20レイヤー以上使っていますが、10未満でもそれなりの品質になったように思います(上で貼った音声サンプルがまさにその例です)
- 品質を改良するために、arXiv:1710.08969 から色々アイデアを借りましたが、逆にDeepVoice3のアイデアで良かったと思えるものに、Decoderの入力に、(メル周波数の次元まで小さくして、Sigmoidを通して得られる)メル周波数スペクトログラムを使うのではなくその前のhidden stateを使う、といったことがありました。勾配がサチりやすいSigmoidをかまないからか、スペクトログラムに対するL1 Lossの減少が確実に速くなりました (22a6748)。
- この記事に貼った音声サンプルにおいて、先頭のaが抜けている例が目立ちますが、過去にやった実験ではこういう例は稀だったので、何かハイパーパラメータを誤っていじったんだと思います(闇
参考
- Wei Ping, Kainan Peng, Andrew Gibiansky, et al, “Deep Voice 3: 2000-Speaker Neural Text-to-Speech”, arXiv:1710.07654, Oct. 2017.
- Jonas Gehring, Michael Auli, David Grangier, et al, “Convolutional Sequence to Sequence Learning”, arXiv:1705.03122, May 2017.
- Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention. [arXiv:1710.08969] | LESS IS MORE
関連記事
Ryuichi Yamamoto
Engineer/Researcher
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.