日本語 End-to-end 音声合成に使えるコーパス JSUT の前処理 [arXiv:1711.00354]
Summary
- コーパス配布先リンク: JSUT (Japanese speech corpus of Saruwatari Lab, University of Tokyo) - Shinnosuke Takamichi (高道 慎之介)
- 論文リンク: arXiv:1711.00354
三行まとめ
- 日本語End-to-end音声合成に使えるコーパスは神、ありがとうございます
- クリーンな音声であるとはいえ、冒頭/末尾の無音区間は削除されていない、またボタンポチッみたいな音も稀に入っているので注意
- 僕が行った無音区間除去の方法(Juliusで音素アライメントを取って云々)を記録しておくので、必要になった方は参考にどうぞ。ラベルファイルだけほしい人は連絡ください
JSUT とは
ツイート引用:
フリーの日本語音声コーパス(単一話者による10時間データ)を公開しました.音声研究等にお役立てください.https://t.co/94ShJY44mA pic.twitter.com/T0etDwD7cS
— Shinnosuke Takamichi (高道 慎之介) (@forthshinji) October 26, 2017
つい先月、JSUT という、日本語 End-to-end 音声合成の研究に使えることを前提に作られた、フリーの大規模音声コーパスが公開されました。詳細は上記リンク先を見てもらうとして、簡単に特徴をまとめると、以下のとおりです。
- 単一日本語女性話者の音声10時間
- 無響室で収録されている、クリーンな音声コーパス 1
- 非営利目的で無料で使える
僕の知る限り、日本語 End-to-end 音声合成に関する研究はまだあまり発展していないように感じていたのですが、その理由の一つに誰でも自由に使えるコーパスがなかったことがあったように思います。このデータセットはとても貴重なので、ぜひ使っていきたいところです。 高道氏およびコーパスを整備してくださった方、本当にありがとうございます。
この記事では、僕が実際に日本語End-to-end音声合成の実験をしようと思った時に、必要になった前処理(最初と最後の無音区間の除去)について書きたいと思います。
問題
まずはじめに、最初と最後の無音区間を除去したい理由には、以下の二つがありました。
- Tacotronのようなattention付きseq2seqモデルにおいて、アライメントを学習するのに不都合なこと。句読点に起因する無音区間ならともかく、最初/最後の無音区間は、テキスト情報からはわからないので、直感的には不要であると思われます。参考までに、DeepVoice2の論文のsection 4.2 では、無音区間をトリミングするのがよかったと書かれています。
- 発話の前、発話の後に、微妙にノイズがある(息を大きく吸う音、ボタンをポチッ、みたいな機械音等)データがあり、そのノイズが不都合なこと。例えばTacotronのようなモデルでは、テキスト情報とスペクトログラムの関係性を学習したいので、テキストに関係のないノイズは可能な限り除去しておきたいところです。参考までに、ボタンポチノイズは 例えば
basic5000/wav/BASIC5000_0008.wavに入っています
最初何も考えずに(ダメですが)データを入れたら、アライメントが上手く学習されないなーと思い、データを見ていたところ、後者に気づいた次第です。
方法
さて、無音区間を除去する一番簡単な方法は、適当にパワーで閾値処理をすることです。しかし、前述の通りボタンをポチッと押したようなノイズは、この方法では難しそうでした。というわけで、少し手間はかかりますが、Juliusで音素アライメントを取って、無音区間を推定することにしました。 以下、Juliusを使ってアライメントファイル(.lab) を作る方法です。コードは、 https://github.com/r9y9/segmentation-kit/tree/jsut にあります。
自分で準備するのが面倒だから結果のラベルファイルだけほしいという方がいれば、連絡をいただければお渡しします。Linux環境での実行を想定しています。僕はUbuntu 16.04で作業しています。
準備
- Julius をインストールする。
/usr/local/bin/juliusにバイナリがあるとします - MeCabをインストールする
- mecab-ipadic-neologd をインストールする
- nnmnkwii のmasterブランチを入れる
pip install mecab-python3 jaconvsudo apt-get install sox- Juliusの音素セグメンテーションツールキットのフォーク (jsutブランチ) をクローンする。クローン先を作業ディレクトリとします
コーパスの場所を設定
params.py というファイルに、コーパスの場所を指定する変数 (in_dir) があるので、設定します。僕の場合、以下のようになっています。
# coding: utf-8
in_dir = "/home/ryuichi/data/jsut_ver1"
dst_dir = "jsut"
音素アライメントの実行
bash run.sh
でまるっと実行できるようにしました。MeCabで読みを推定するなどの処理は、この記事を書いている時点では a.py, b.py, c.py, d.pyというファイルに書かれています。 適当なファイル名で申し訳ありませんという気持ちですが、自分のための書いたコードはこうなってしまいがちです、申し訳ありません。
7000ファイル以上処理するので、三十分くらいかかります。./jsut というディレクトリに、labファイルができていれば正常に実行完了です。最後に、
Failed number of utterances: 87
のように、アライメントに失敗したファイル数が表示されるようになっています。失敗の理由には、MeCabでの読みの推定に失敗した(特に数字)などがあります。手で直すことも可能なのですが(実際に一度はやろうとした)非常に大変なので、多少失敗してもよいので大雑把にアライメントを取ることを目的として、スクリプトを作りました。
なお、juliusはwavesurferのフォーマットでラベルファイルを吐きますが、HTKのラベルフォーマットの方が僕には都合がよかったので、変換するようにしました。
コーパスにパッチ
便宜上、下記のようにwavディレクトリと同じ階層にラベルファイルがあると都合がよいので、僕はそのようにします。
tree ~/data/jsut_ver1/ -d -L 2
/home/ryuichi/data/jsut_ver1/
├── basic5000
│ ├── lab
│ └── wav
├── countersuffix26
│ ├── lab
│ └── wav
├── loanword128
│ ├── lab
│ └── wav
├── onomatopee300
│ ├── lab
│ └── wav
├── precedent130
│ ├── lab
│ └── wav
├── repeat500
│ ├── lab
│ └── wav
├── travel1000
│ ├── lab
│ └── wav
├── utparaphrase512
│ ├── lab
│ └── wav
└── voiceactress100
├── lab
└── wav
以下のコマンドにより、生成されたラベルファイルをコーパス配下にコピーします。この処理は、run.sh では実行しないようになっているので、必要であれば自己責任でおこなってください。
python d.py
ラベル活用例
https://gist.github.com/r9y9/db6b5484a6a5deca24e81e76cb17e046 のようなコードを書いて、ボタンポチ音が末尾に入っている basic5000/wav/BASIC5000_0008.wav に対して無音区間削除を行ってみると、結果は以下のようになります。
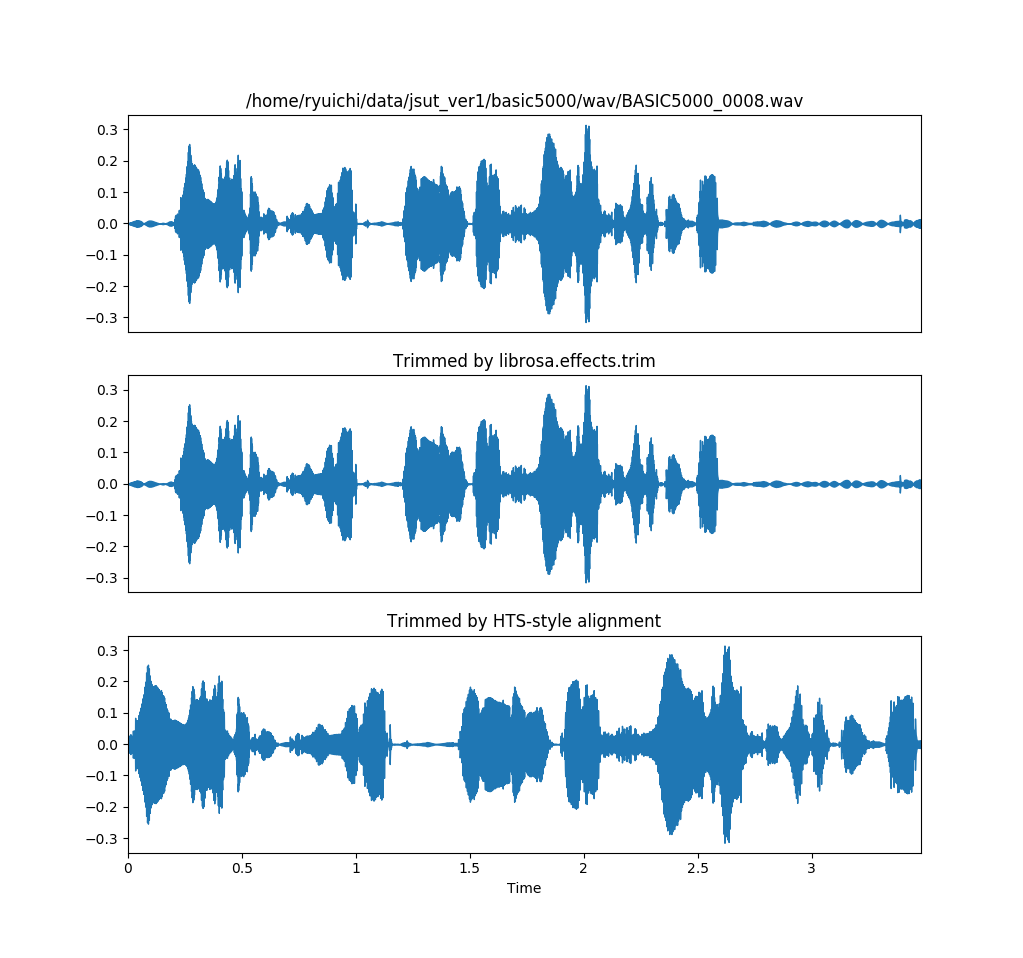
パワーベースの閾値処理では上手くいかない一方で2、音素アライメントを使った方法では上手く無音区間除去ができています。その他、数十サンプルを目視で確認しましたが、僕の期待どおり上手くいっているようでした。めでたし。
おわり
以上です。End-to-end系のモデルにとってはデータは命であり、このコーパスは神であります。このコーパスを使って、同じように前処理をしたい人の参考になれば幸いです。
いま僕はこのコーパスを使って、日本語end-to-end音声合成の実験も少しやっているので、まとまったら報告しようと思っています。
これさ、ASJとかで発表しない?絶対に価値あると思う。諸々のサポートはしますよ。
— Shinnosuke Takamichi (高道 慎之介) (@forthshinji) November 8, 2017
コーパスを作った本人氏にASJで発表しないかと勧誘を受けていますが、現在の予定は未定です^q^
参考
- Ryosuke Sonobe, Shinnosuke Takamichi and Hiroshi Saruwatari, “JSUT corpus: free large-scale Japanese speech corpus for end-to-end speech synthesis,” arXiv preprint, 1711.00354, 2017.
- Sercan Arik, Gregory Diamos, Andrew Gibiansky, et al, “Deep Voice 2: Multi-Speaker Neural Text-to-Speech”, arXiv:1705.08947, 2017.
Ryuichi Yamamoto
Engineer/Researcher
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.