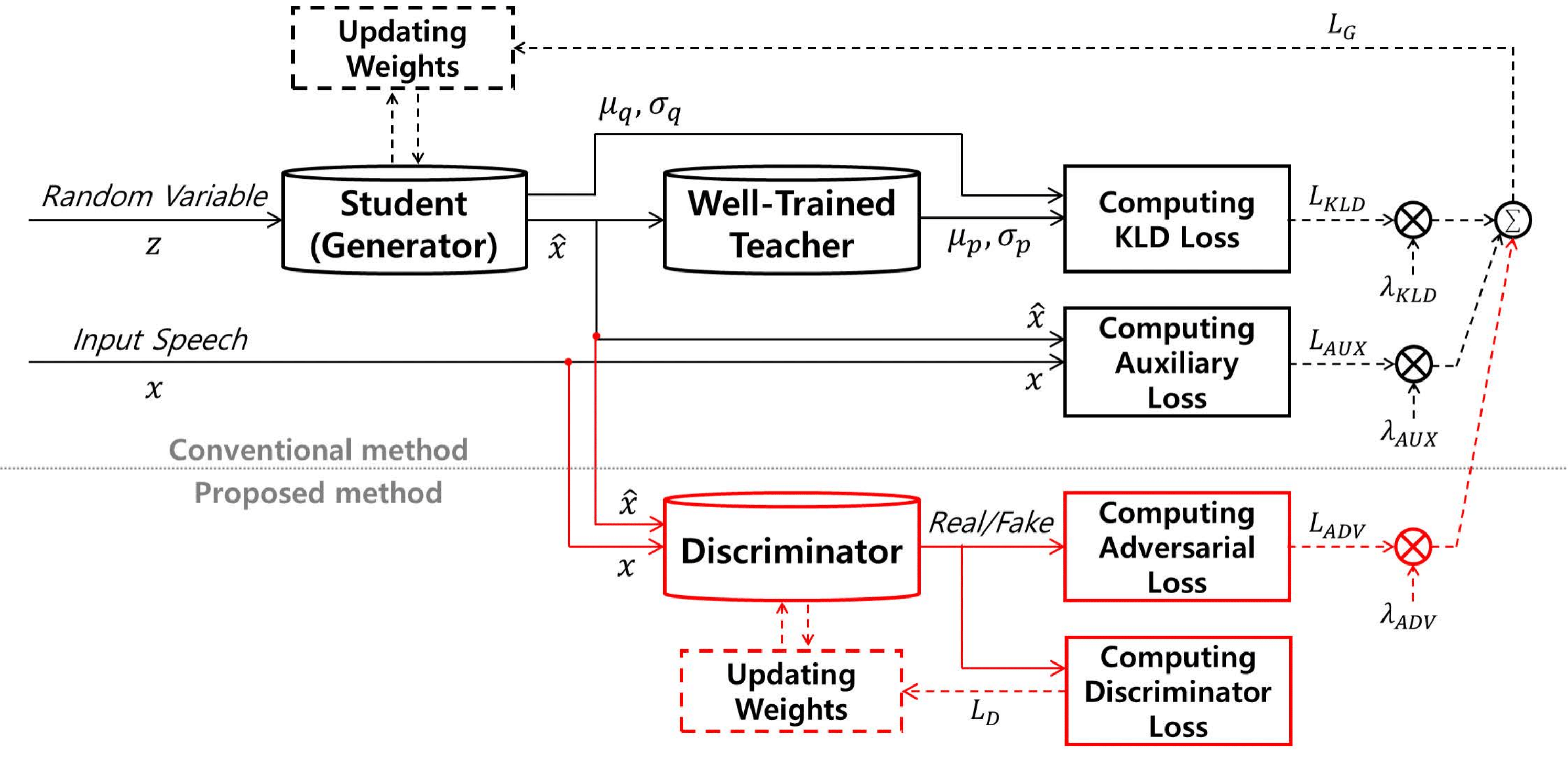
This paper proposes an effective probability density distillation (PDD) algorithm for WaveNet-based parallel waveform generation (PWG) systems. Recently proposed teacher-student frameworks in the PWG system have successfully achieved a real-time generation of speech signals. However, the difficulties optimizing the PDD criteria without auxiliary losses result in quality degradation of synthesized speech. To generate more natural speech signals within the teacher-student framework, we propose a novel optimization criterion based on generative adversarial networks (GANs). In the proposed method, the inverse autoregressive flow-based student model is incorporated as a generator in the GAN framework, and jointly optimized by the PDD mechanism with the proposed adversarial learning method. As this process encourages the student to model the distribution of realistic speech waveform, the perceptual quality of the synthesized speech becomes much more natural. Our experimental results verify that the PWG systems with the proposed method outperform both those using conventional approaches, and also autoregressive generation systems with a well-trained teacher WaveNet.
Audio samples
There are 8 different systems, that include 6 parallel waveform generation systems (Student-*) trained by different optimization criteria as follows:
Student-KL: KLD loss (Ablation study; not used for subjective evaluations).
Student-KLAX: KLD and STFT auxiliary losses.
Student-KLAXAD: KLD, STFT, and adversarial losses (proposed).
Student-KLAXAD*: Weights optimized version of the above (proposed).
Copy-synthesis
Japanese female speaker
Sample 1
Ground truth
Teacher
Student-AX
Student-AXAV
Student-KL
Student-KLAX
Student-KLAXAD
Student-KLAXAD*
Sample 2
Ground truth
Teacher
Student-AX
Student-AXAV
Student-KL
Student-KLAX
Student-KLAXAD
Student-KLAXAD*
Sample 3
Ground truth
Teacher
Student-AX
Student-AXAV
Student-KL
Student-KLAX
Student-KLAXAD
Student-KLAXAD*
Sample 4
Ground truth
Teacher
Student-AX
Student-AXAV
Student-KL
Student-KLAX
Student-KLAXAD
Student-KLAXAD*
Sample 5
Ground truth
Teacher
Student-AX
Student-AXAV
Student-KL
Student-KLAX
Student-KLAXAD
Student-KLAXAD*
References
[1]: W. Ping, K. Peng, and J. Chen, “ClariNet: Parallel wave generation in end-to-end text-to-speech,” in Proc. ICLR, 2019 (arXiv).
Acknowledgements
Work performed with nVoice, Clova Voice, Naver Corp.
Citation
@inproceedings{Yamamoto2019,
author={Ryuichi Yamamoto and Eunwoo Song and Jae-Min Kim},
title={{Probability Density Distillation with Generative Adversarial Networks for High-Quality Parallel Waveform Generation}},
year=2019,
booktitle={Proc. Interspeech 2019},
pages={699--703},
doi={10.21437/Interspeech.2019-1965},
url={http://dx.doi.org/10.21437/Interspeech.2019-1965}
}
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.