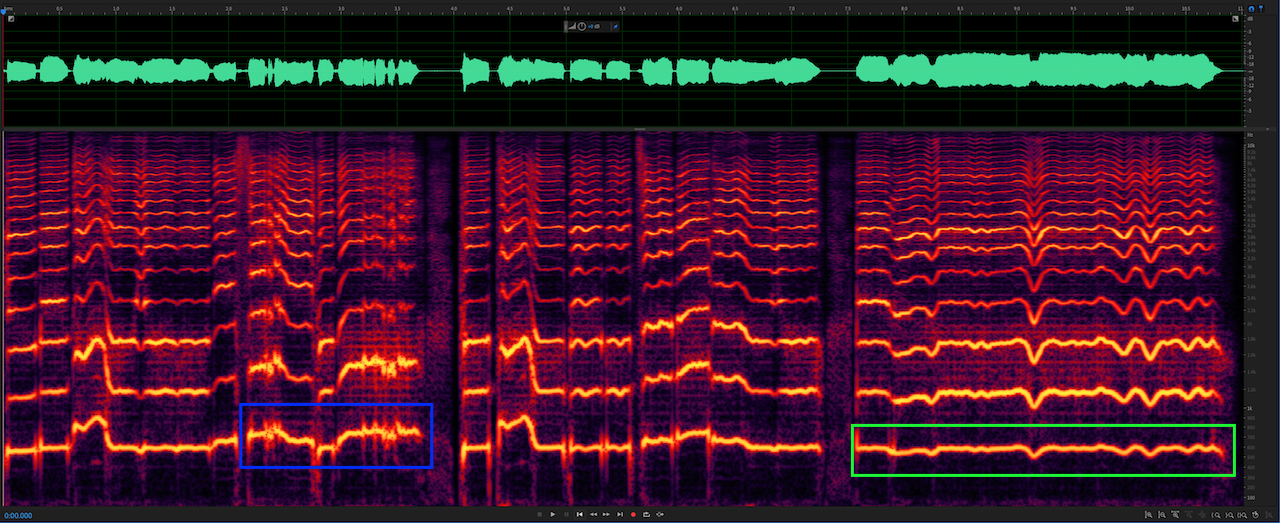
2023/02/27: Added error cases to address reviewer’s comments. See Error cases.
2022/11/27: Added samples of diffusion-based acoustic models. See Bonus samples.
2022/10/18: Created the demo page.
Authors
Ryuichi Yamamoto (LINE Corp., Nagoya University)
Reo Yoneyama (Nagoya University)
Tomoki Toda (Nagoya University)
Abstract
This paper describes the design of NNSVS, an open-source software for neural network-based singing voice synthesis research. NNSVS is inspired by Sinsy, an open-source pioneer in singing voice synthesis research, and provides many additional features such as multi-stream models, autoregressive fundamental frequency models, and neural vocoders. Furthermore, NNSVS provides extensive documentation and numerous scripts to build complete singing voice synthesis systems. Experimental results demonstrate that our best system significantly outperforms our reproduction of Sinsy and other baseline systems. The toolkit is available at https://github.com/nnsvs/nnsvs.
Systems
The following table summarizes the systems used in our experiments. All the models were trained on Namine Ritsu’s database [1].
System
Acoustic Features
Multi-stream Architecture
Autoregressive streams
Vocoder
Sinsy [2]
MGC, LF0, VUV, BAP
No
-
hn-uSFGAN [5]
Sinsy (w/ pitch correction)
MGC, LF0, VUV, BAP
No
-
hn-uSFGAN
Sinsy (w/ vibrato modeling)
MGC, LF0, VUV, BAP
No
-
hn-uSFGAN
Muskits RNN [3]
MEL
No
-
HiFi-GAN [6]
DiffSinger [4]
MEL, LF0, VUV
Yes
-
hn-HiFi-GAN
NNSVS-Mel v1
MEL, LF0, VUV
Yes
-
hn-uSFGAN
NNSVS-Mel v2
MEL, LF0, VUV
Yes
LF0
hn-uSFGAN
NNSVS-Mel v3
MEL, LF0, VUV
Yes
MEL, LF0
hn-uSFGAN
NNSVS-WORLD v0 [1]
MGC, LF0, VUV, BAP
No
-
WORLD
NNSVS-WORLD v1
MGC, LF0, VUV, BAP
Yes
-
hn-uSFGAN
NNSVS-WORLD v2
MGC, LF0, VUV, BAP
Yes
LF0
hn-uSFGAN
NNSVS-WORLD v3
MGC, LF0, VUV, BAP
Yes
MGC, LF0
hn-uSFGAN
NNSVS-WORLD v4
MGC, LF0, VUV, BAP
Yes
MGC, LF0, BAP
hn-uSFGAN
hn-HiFI-GAN (A/S)
MEL, LF0, VUV
-
-
hn-HiFi-GAN
hn-uSFGAN-Mel (A/S)
MEL, LF0, VUV
-
-
hn-uSFGAN
hn-uSFGAN-WORLD (A/S)
MGC, LF0, VUV, BAP
-
-
hn-uSFGAN
Notes on baselines
Muskits and DiffSinger baseline systems were trained with thier offical code (Muskits and DiffSinger).
hn-HiFi-GAN is the vocoder used by DiffSinger. The detail of its implementation can be found here.
Sinsy systems are based on NNSVS’s implementation.
NNSVS-WORLD v0 uses the model trained with the earlier version of NNSVS (as of Nov. 2021) [1]. See here for details.
Notes on NNSVS systems
The code for reproducing experiments are available here.
Samples
The following samples are vocal only. Mixed demo can be found here.
SVS
Samples generated from musical score.
Sample 1: 1st color
Recording
Sinsy
Sinsy (with pitch correction)
Sinsy (with vibrato modeling)
Muskits RNN
DiffSinger
NNSVS-Mel v1
NNSVS-Mel v2
NNSVS-Mel v3
NNSVS-WORLD v0
NNSVS-WORLD v1
NNSVS-WORLD v2
NNSVS-WORLD v3
NNSVS-WORLD v4
Sample 2: ARROW
Recording
Sinsy
Sinsy (with pitch correction)
Sinsy (with vibrato modeling)
Muskits RNN
DiffSinger
NNSVS-Mel v1
NNSVS-Mel v2
NNSVS-Mel v3
NNSVS-WORLD v0
NNSVS-WORLD v1
NNSVS-WORLD v2
NNSVS-WORLD v3
NNSVS-WORLD v4
Sample 3: BC
Recording
Sinsy
Sinsy (with pitch correction)
Sinsy (with vibrato modeling)
Muskits RNN
DiffSinger
NNSVS-Mel v1
NNSVS-Mel v2
NNSVS-Mel v3
NNSVS-WORLD v0
NNSVS-WORLD v1
NNSVS-WORLD v2
NNSVS-WORLD v3
NNSVS-WORLD v4
Sample 4: Close to you
Recording
Sinsy
Sinsy (with pitch correction)
Sinsy (with vibrato modeling)
Muskits RNN
DiffSinger
NNSVS-Mel v1
NNSVS-Mel v2
NNSVS-Mel v3
NNSVS-WORLD v0
NNSVS-WORLD v1
NNSVS-WORLD v2
NNSVS-WORLD v3
NNSVS-WORLD v4
Sample 5: ERROR
Recording
Sinsy
Sinsy (with pitch correction)
Sinsy (with vibrato modeling)
Muskits RNN
DiffSinger
NNSVS-Mel v1
NNSVS-Mel v2
NNSVS-Mel v3
NNSVS-WORLD v0
NNSVS-WORLD v1
NNSVS-WORLD v2
NNSVS-WORLD v3
NNSVS-WORLD v4
A/S
Samples generated from extracted features (i.e., analysis-by-synthesis).
Sample 1: 1st color
Recording
hn-HiFi-GAN
hn-USFGAN-Mel
hn-USFGAN-WORLD
Sample 2: ARROW
Recording
hn-HiFi-GAN
hn-USFGAN-Mel
hn-USFGAN-WORLD
Sample 3: BC
Recording
hn-HiFi-GAN
hn-USFGAN-Mel
hn-USFGAN-WORLD
Sample 4: Close to you
Recording
hn-HiFi-GAN
hn-USFGAN-Mel
hn-USFGAN-WORLD
Sample 5: ERROR
Recording
hn-HiFi-GAN
hn-USFGAN-Mel
hn-USFGAN-WORLD
Mixed demo
System: NNSVS-WORLD v4
Sample 1
ERROR (from test data)
Sample 2
ARROW (from test data)
Sample 3
WAVE (from training data)
Bonus samples
We integrated the diffusion model for SVS [4] to improve naturalness of synthetic voice.
The following table summarizes the systems for bonus samples.
System
Acoustic Features
Autoregressive streams
Diffusion streams
Vocoder
NNSVS-WORLD v4*
MGC, LF0, VUV, BAP
LF0, MGC, BAP
-
SiFi-GAN [7]
NNSVS-Mel v5
MEL, lF0, VUV
LF0
MEL
SiFi-GAN
NNSVS-WORLD v5
MGC, LF0, VUV, BAP
LF0
MGC, BAP
SiFi-GAN
NNSVS-WORLD v4* is the best model (as of 2022/09) reported in our paper with the following two changes:
sampling rate was changed from 24 kHz to 48 kHz
the vocoder was changed from hn-uSFGAN to SiFI-GAN [7].
NNSVS-Mel v5 and NNSVS-WORLD v5 are the systems using diffusion-based multi-stream acoustic models.
Note that we used 48 kHz sampling rate for the additional experiments.
As shown in the figure (blue: discontinous F0; green: unstable vibrato), the pitch contour of the DiffSinger is sometimes unstable.
Acknowledgments
This work was partly supported by JST CREST Grant Number JPMJCR19A3.
Appendix
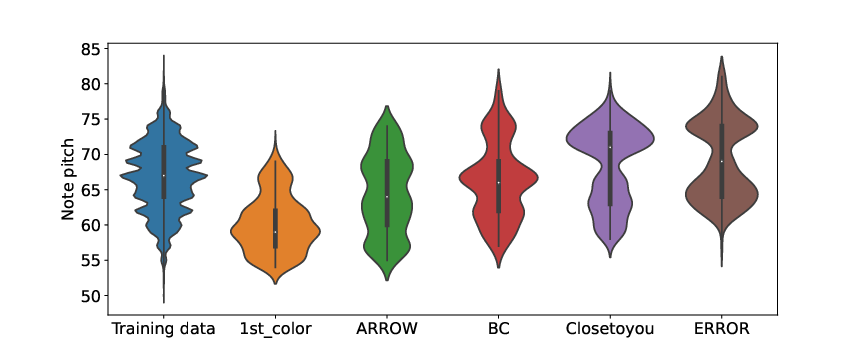
Note pitch distribution
We selected test songs to cover a wide range of note pitches. Their distributions are shown in the following figure.
Pitch is presented as MIDI note number, where A4 (69) corresponds to 440 Hz.
The lowerest and highest notes of the test songs were D#4 (155.6 Hz) and A5 (880 Hz), whereas those of the training data were D#3 (146.8 Hz) and B5 (987.8 Hz).
[2] Y. Hono, K. Hashimoto, K. Oura, et al., “Sinsy: A deep neural network-based singing voice synthesis system,” IEEE/ACM Trans. on Audio, Speech, and Language Processing, vol. 29, pp. 2803.
[3] J. Shi, S. Guo, T. Qian, et al., “Muskits: an End-to-end Music Processing Toolkit for Singing Voice Synthesis,” in Proc. Interspeech, 2022, pp. 4277–4281.
[4] J. Liu, C. Li, Y. Ren, et al., “DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism”, AAAI, vol. 36, no. 10, pp. 11020-11028, Jun. 2022.
[5] R. Yoneyama, Y.-C. Wu, and T. Toda, “Unified Source-Filter GAN with Harmonic-plus-Noise Source Excitation Generation,” in Proc. Interspeech, 2022, pp. 848–852.
[6] J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,” NeurIPS, vol. 33, pp. 17 022–17 033, 2020.
[7] R. Yoneyama, Y.-C. Wu, and T. Toda, “Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder." arXiv preprint arXiv:2210.15533, 2022.
[8] Y. Wang, X. Wang, P. Zhu, et al., “Opencpop: a high-quality open source chinese popular song corpus for singing voice synthesis," arXiv:2201.07429, 2022.
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.