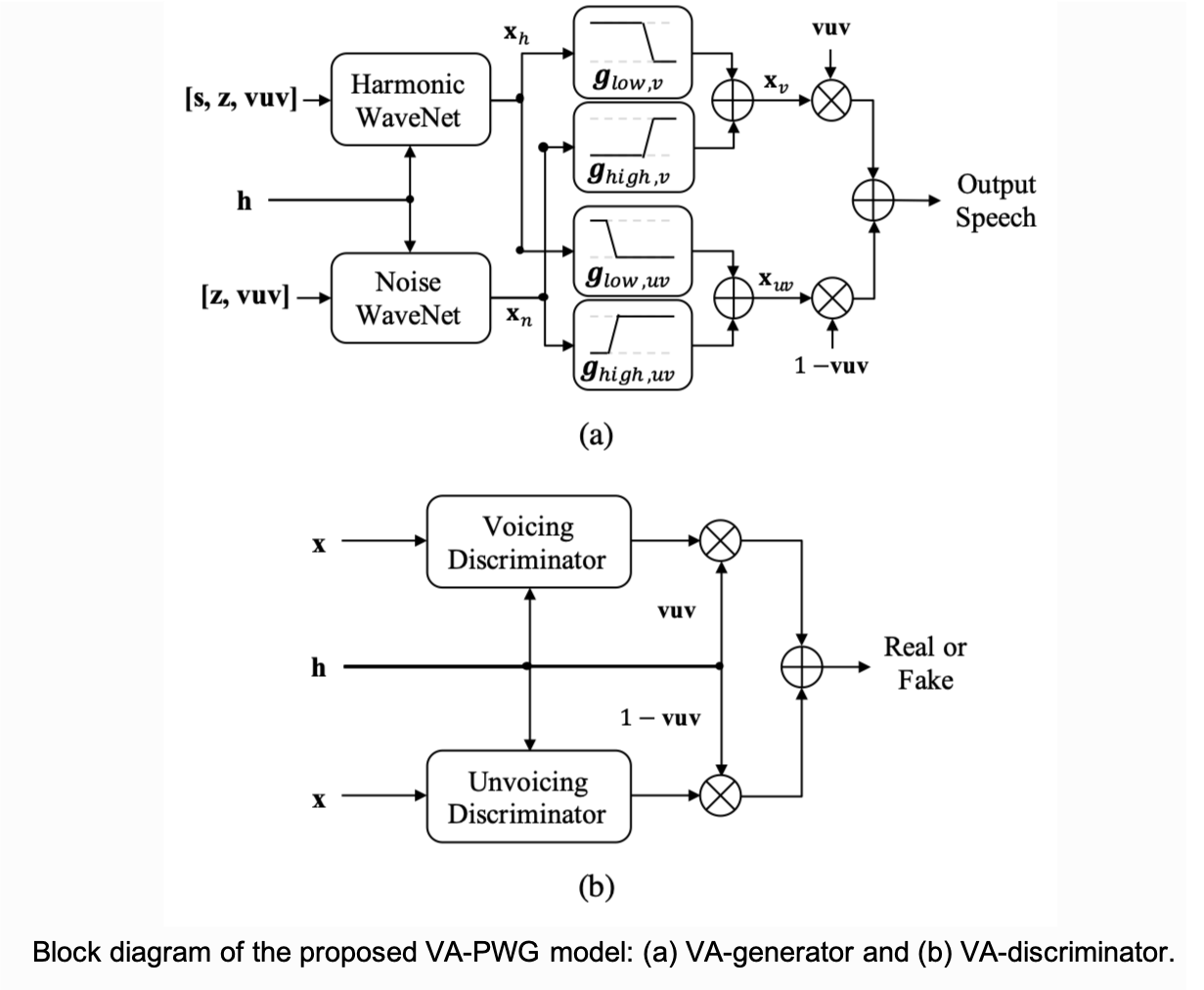
This letter proposes a voicing-aware Parallel Wave- GAN (VA-PWG) vocoder for a neural text-to-speech (TTS) system. To generate a high-quality speech waveform, it is important to reflect the distinct characteristics of voiced and unvoiced speech signals well. However, it is difficult for the conventional PWG model to accurately represent this condition, since the single unified architectures of the generator and discriminator are insufficient to capture those characteristics. In the proposed method, both the generator and discriminator are divided into their subnetworks to individually model the voicing state-dependent characteristics of a speech signal. In particular, a VA-generator consisting of two sub-WaveNets generates the harmonic and noise components of a speech signal by inputting pitch-dependent sine wave and Gaussian noise sources, respectively. Likewise, a VA-discriminator consisting of two sub-discriminators learns the distinct characteristics of harmonic and noise components by feeding the voiced and unvoiced waveforms, respectively. Subjective evaluation results verified the effectiveness of the proposed VA-PWG vocoder by achieving a 4.25 mean opinion score from a speaker-independent training scenario that was 11% higher than that of a conventional PWG vocoder.
TTS samples
M1 (male)
Sample 1: “鹿児島県で最大震度三を観測しています。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
Sample 2: “葉加瀬太郎の情熱大陸です。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
Sample 3: “それでうちの部は半分に減らされる。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
M2 (male)
Sample 1: “ヨメの、レオンティーンさんですね。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
Sample 2: “御予約は、二泊三日ですね。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
Sample 3: “わたさちの、ローリーさんですね。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
F1 (female)
Sample 1: “かわいそうに、助けてやらなくてはと、家に連れて帰りましたとさ。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
Sample 2: “失礼のないよう、笑顔で挨拶して。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
Sample 3: “照れていたので、ちょっと意外な気がしましたー。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
F2 (female)
Sample 1: “そして目に留まったのは、お気に入りの居酒屋の前にあるゴミの山。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
Sample 2: “今ひとつ、時間が足りず。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
Sample 3: “実はこの道の先に、高い山があってね。”
Recording
WaveNet
PWG
VA-PWG-G
VA-PWG-D
VA-PWG-GD (proposed)
Acknowledgements
Work performed with nVoice, Clova Voice, Naver Corp.
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.