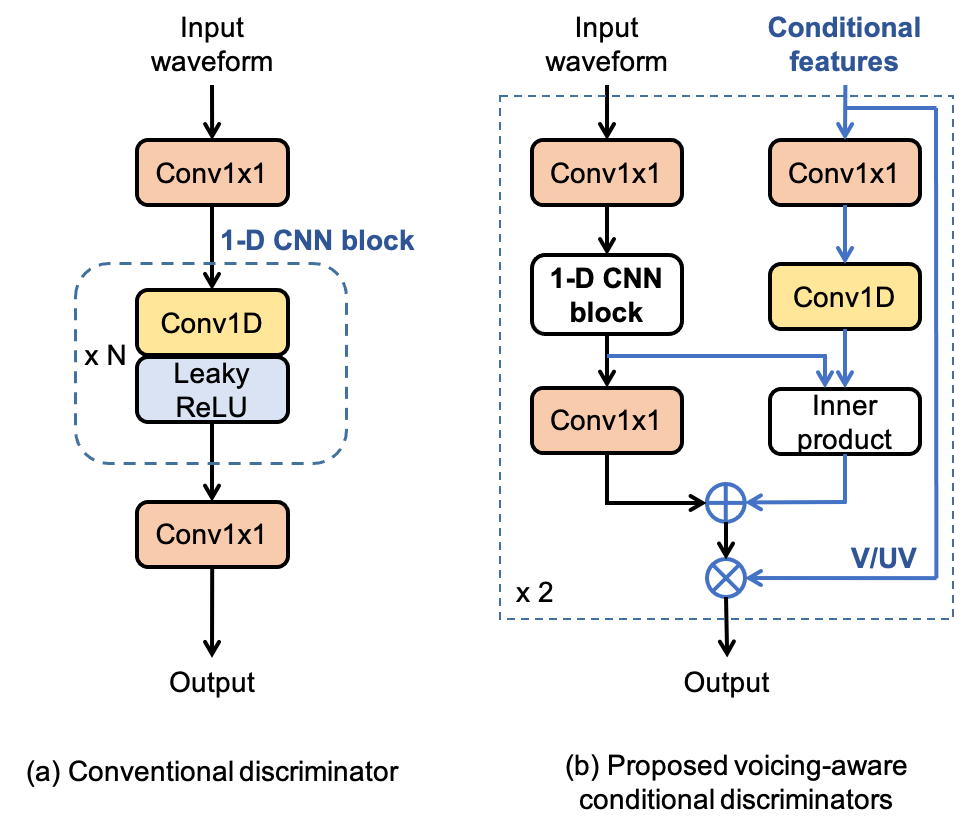
This paper proposes voicing-aware conditional discriminators for Parallel WaveGAN-based waveform synthesis systems. In this framework, we adopt a projection-based conditioning method that can significantly improve the discriminator’s performance. Furthermore, the conventional discriminator is separated into two waveform discriminators for modeling voiced and unvoiced speech. As each discriminator learns the distinctive characteristics of the harmonic and noise components, respectively, the adversarial training process becomes more efficient, allowing the generator to produce more realistic speech waveforms. Subjective test results demonstrate the superiority of the proposed method over the conventional Parallel WaveGAN and WaveNet systems. In particular, our speaker-independently trained model within a FastSpeech 2 based text-to-speech framework achieves the mean opinion scores of 4.20, 4.18, 4.21, and 4.31 for four Japanese speakers, respectively.
$D^{\mathrm{{v}}}$: 1-D dilated CNN discrimiantor with the reseptive field size of 127.
$D^{\mathrm{{uv}}}$: 1-D CNN discrimiantor with the reseptive field size of 13.
PWG denotes Parallel WaveGAN for short. Systems S2-PWG and S3-PWG-cGAN-D used $D^{\mathrm{{v}}}$ as the primary discriminator. Note that all the Parallel WaveGAN systems used the same generator architecture and training configurations; they only differed in the discriminator settings.
Analysis/synthesis
F1 (female)
Sample 1
Recording
S1-WaveNet
S2-PWG
S7-PWG-V/UV-D (ours)
S3-PWG-cGAN-D
S4-PWG-V/UV-D
S5-PWG-V/UV-D
S6-PWG-V/UV-D
F2 (female)
Sample 1
Recording
S1-WaveNet
S2-PWG
S7-PWG-V/UV-D (ours)
S3-PWG-cGAN-D
S4-PWG-V/UV-D
S5-PWG-V/UV-D
S6-PWG-V/UV-D
M1 (male)
Sample 1
Recording
S1-WaveNet
S2-PWG
S7-PWG-V/UV-D (ours)
S3-PWG-cGAN-D
S4-PWG-V/UV-D
S5-PWG-V/UV-D
S6-PWG-V/UV-D
M2 (male)
Sample 1
Recording
S1-WaveNet
S2-PWG
S7-PWG-V/UV-D (ours)
S3-PWG-cGAN-D
S4-PWG-V/UV-D
S5-PWG-V/UV-D
S6-PWG-V/UV-D
Text-to-speech
FastSpeech 2 ([3]) based acoustic models were used for text-to-speech experiments.
F1 (female)
Sample 1
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
Sample 2
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
Sample 3
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
F2 (female)
Sample 1
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
Sample 2
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
Sample 3
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
M1 (male)
Sample 1
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
Sample 2
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
Sample 3
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
M2 (male)
Sample 1
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
Sample 2
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
Sample 3
Recording
FastSpeech 2 + WaveNet
FastSpeech 2 + PWG
FastSpeech 2 + PWG-V/UV-D (ours)
FastSpeech 2 + PWG-cGAN-D
Bonus: Analysis/synthesis (English)
Samples for CMU ARCTIC database are provided as follows. The models were trained using total six speakers (clb, slt, bdl, rms, jmk, and ksp) in a speaker-independent way.
The models were similary configured as the above experiments.
clb (female)
Sample 1
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 2
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 3
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
slt (female)
Sample 1
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 2
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 3
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
bdl (male)
Sample 1
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 2
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 3
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
rms (male)
Sample 1
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 2
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 3
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
jmk (male)
Sample 1
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 2
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 3
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
ksp (male)
Sample 1
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 2
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
Sample 3
Recording
PWG
PWG-cGAN-D
PWG-V/UV-D (ours)
References
[1] W. Ping, K. Peng, and J. Chen, “ClariNet: Parallel wave generation in end-to-end text-to-speech,” in Proc. ICLR, 2019 arXiv.
[2] R Yamamoto, E Song, and J.-M Kim, “Parallel WaveGAN:A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram,” in Proc. ICASSP, 2020, pp. 6199–6203. arXiv.
[3] Y Ren, C Hu, T Qin, S Zhao, Z Zhao, and T.-Y Liu, “Fast-speech 2: Fast and high-quality end-to-end text-to-speech,”arXiv preprint arXiv:2006.04558, 2020. arXiv.
Acknowledgements
Work performed with nVoice, Clova Voice, Naver Corp.
Citation
@inproceedings{yamamoto2020parallel,
title={Parallel waveform synthesis based on generative adversarial networks with voicing-aware conditional discriminators},
author={Ryuichi Yamamoto and Eunwoo Song and Min-Jae Hwang and Jae-Min Kim},
booktitle="Proc. of ICASSP (in press)",
year={2021},
}
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.