【音声合成編】Statistical Parametric Speech Synthesis Incorporating Generative Adversarial Networks [arXiv:1709.08041]
10/11 追記: IEEE TASLPのペーパー (Open access) が公開されたようなので、リンクを貼っておきます: https://ieeexplore.ieee.org/document/8063435/
arXiv論文リンク: arXiv:1709.08041
前回の記事 の続きです。音響モデルの学習にGANを使うというアイデアは、声質変換だけでなく音声合成にも応用できます。CMU ARCTIC を使った英語音声合成の実験を行って、ある程度良い結果がでたので、まとめようと思います。音声サンプルだけ聴きたい方は真ん中の方まで読み飛ばしてください。
- コードはこちら: r9y9/gantts | PyTorch implementation of GAN-based text-to-speech and voice conversion (VC) (VCのコードも一緒です)
- 音声サンプル付きデモノートブックはこちら: The effects of adversarial training in text-to-speech synthesis | nbviewer
前回の記事でも書いた注意書きですが、厳密に同じ結果を再現しようとは思っていません。同様のアイデアを試す、といったことに主眼を置いています。
実験
実験条件
CMU ARCTIC から、話者 slt のwavデータそれぞれ1131発話すべてを用います。
Merlin の slt デモの条件と同様に、1000を学習用、126を評価用、残り5をテスト用にします。継続長モデル(state-level)には Bidirectional-LSTM RNN を、音響モデルには Feed-forward型 のニューラルネットを使用しました1。継続長モデル、音響モデルの両方にGANを取り入れました。論文の肝である ADV loss についてですが、mgcのみ(0次は除く)を使って計算するパターンと、mgc + lf0で計算するパターンとで比較しました2。
実験の結果 (ADV loss: mgcのみ) は、 a5ec247 をチェックアウトして、下記のシェルを実行すると再現できます。
./tts_demo.sh tts_test
データのダウンロード、特徴抽出、モデル学習、音声サンプル合成まで一通り行われます。tts_test の部分は何でもよいです。tensorboard用に吐くログイベント名、モデル出力先、音声サンプル出力先の決定に使われます。詳細はコードを参照ください。 (ADV loss: mgc + lf0) の結果は、ハイパーパラメータを下記のように変更してシェルを実行すると再現できます。
diff --git a/hparams.py b/hparams.py
index d82296c..e73dc57 100644
--- a/hparams.py
+++ b/hparams.py
@@ -175,7 +175,7 @@ tts_acoustic = tf.contrib.training.HParams(
# Streams used for computing adversarial loss
# NOTE: you should probably change discriminator's `in_dim`
# if you change the adv_streams
- adversarial_streams=[True, False, False, False],
+ adversarial_streams=[True, True, False, False],
# Don't switch this on unless you are sure what you are doing
# If True, you will need to adjast `in_dim` for discriminator.
# Rationale for this is that power coefficients are less meaningful
@@ -202,7 +202,7 @@ tts_acoustic = tf.contrib.training.HParams(
# Discriminator
discriminator="MLP",
discriminator_params={
- "in_dim": 24,
+ "in_dim": 25,
"out_dim": 1,
"num_hidden": 2,
"hidden_dim": 256,
変換音声の比較
音響モデルのみ適用 (ADV loss: mgcのみ)
継続長モデルを適用しない、かつ ADV lossにmgcのみを用いる場合です。
- 自然音声
- ベースライン
- GAN
の順に音声を貼ります。聴きやすいように、soxで音量を正規化しています。
arctic_b0535
arctic_b0536
arctic_b0537
arctic_b0538
arctic_b0539
VCの場合と同じように、音声の明瞭性が上がったように思います。
音響モデル+継続長モデルを適用 (ADV loss: mgcのみ)
arctic_b0535
arctic_b0536
arctic_b0537
arctic_b0538
arctic_b0539
音声の明瞭性が上がっているとは思いますが、継続長に関しては、ベースライン/GANで差異がほとんどないように感じられると思います。これは、(僕が実験した範囲では少なくとも)DiscriminatorがGeneartorに勝ちやすくて (音響モデルの場合は、そんなことはない)、 ADV lossが下がるどころか上がってしまい、結果 MGE lossを最小化する場合とほとんど変わっていない、という結果になっています。論文に記載の内容とは異なり、state-levelの継続長モデルではあるものの、ハイパーパラメータなどなどいろいろ変えて試したのですが、上手くいきませんでした。
ADV loss: mgc vs mgc + lf0
次に、ロスの比較です。F0の変化に着目しやすいように、継続長モデルを使わず、音響モデルのみを適用します。
- 自然音声
- ADV loss (mgcのみ, 24次元)
- ADV loss (mgc + lf0, 25次元)
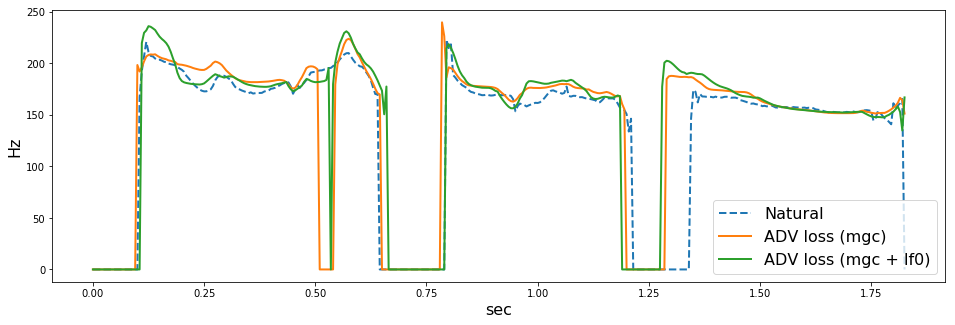
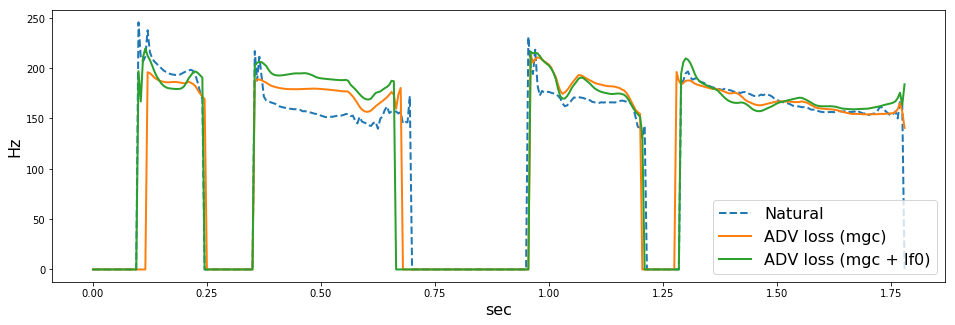
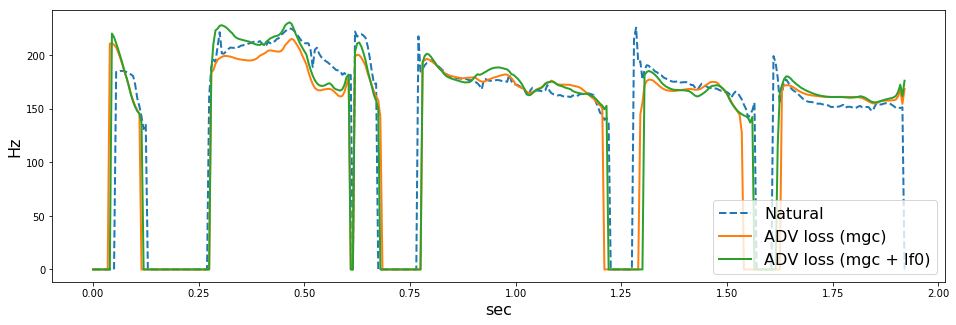
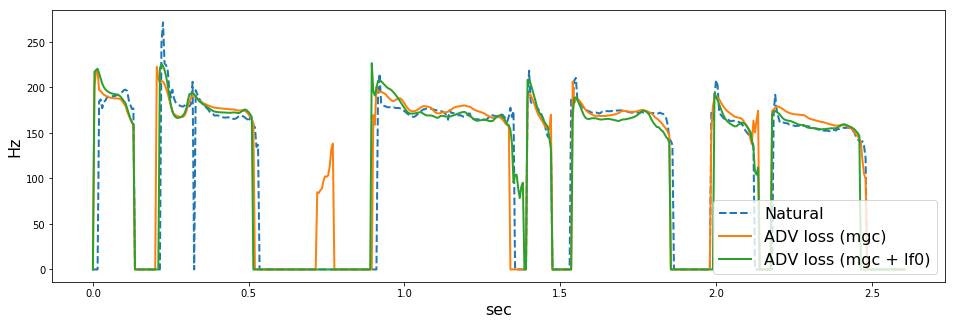
の順に音声を貼ります。また、WORLD (dio + stonemask) で分析したF0の可視化結果も併せて貼っておきます。
arctic_b0535
arctic_b0536
arctic_b0537
arctic_b0538
arctic_b0539
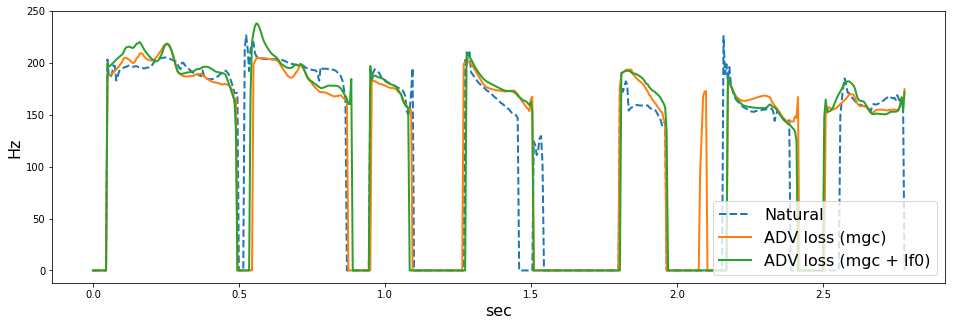
どうでしょうか。上手くいっている場合も(arctic_b537とか)あれば、上手くいっていない場合 (arctic_b539とか) もあるように思います。僕にはF0が不自然に揺れているように感じ場合が多くありました。ここでは5つしか音声を貼っていませんが、その他126個の評価用音声でも聴き比べていると、ADV lossにF0を入れない方がよい気がしました(あくまで僕の主観ですが
このあたりは、F0の抽出法、補間法に強く依存しそうです。今回は、F0抽出のパラメータをまったくチューニングしていないので、そのせいもあった(f0分析エラーに引っ張られて悪くなった)のかもしれません。
Global variance は補償されているのか?
F0の話は終わりで、スペクトル特徴量に着目して結果を分析していきます。以下、ADV loss (mgcのみ)、継続長モデル+音響モデルを適用したサンプルでの分析結果です。
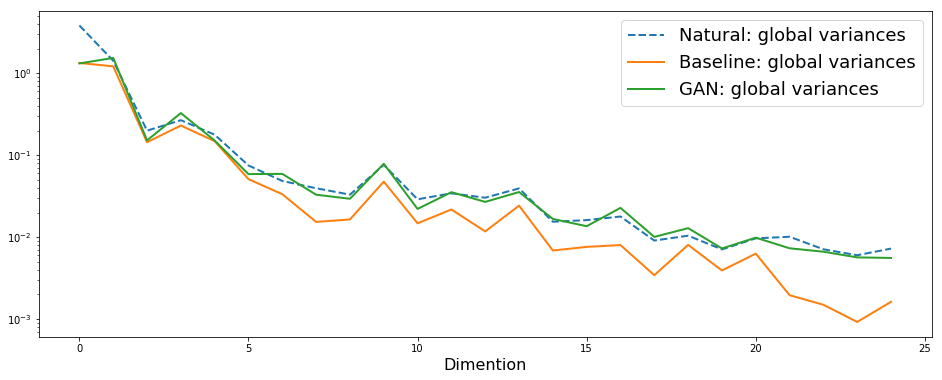
大まかに、論文で示されているのと同様の結果が得られました。なお、これは arctic_b0537 の一発話に対して計算したもので、テストセットの平均ではありません(すいません)。また、これはテストセット中のサンプルの中で、GVが補償されていることがわかりやすい例をピックアップしました。ただし、他のテストサンプルにおいても同様の傾向が見られるのは確認しています。
Modulation spectrum (変調スペクトル) は補償されているのか?
評価用の音声126発話それぞれで変調スペクトルを計算し、それらの平均を取り、適当な特徴量の次元をピックアップしたものを示します。横軸は変調周波数です。一番右端が50Hzです。
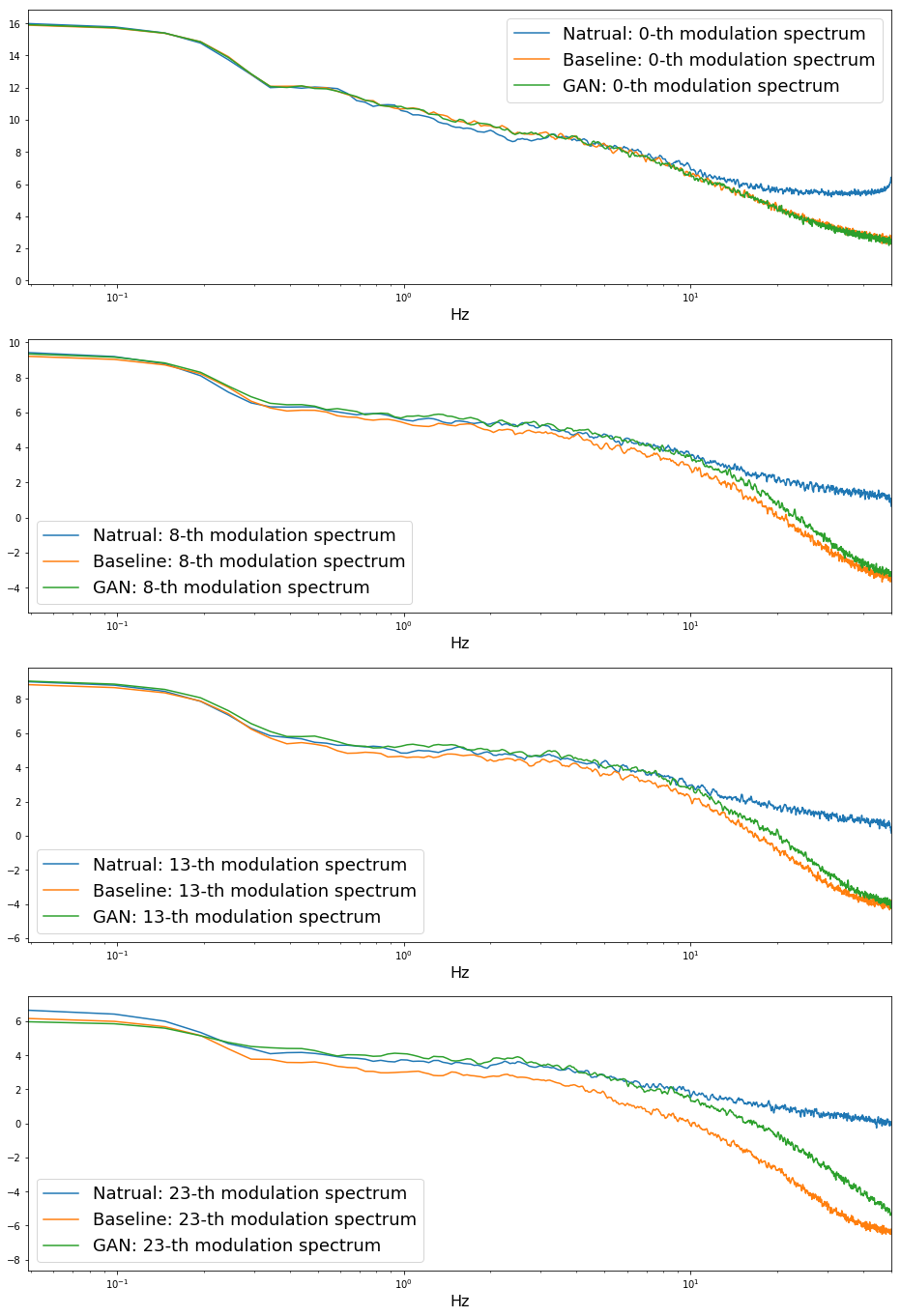
arctic_b0537 の一発話に対して計算したものです。VCの場合とは異なり、ベースライン、GANともに、低次元であっても10Hzを越えた辺りから自然音声とは大きく異っています。これはなぜなのか、僕にはまだわかっていません。また、VCの場合と同様に、高次元になるほど、GANベースの方が変調スペクトルは自然音声に近いこともわかります。GANによって、変調スペクトルはある程度補償されていると言えると思います。
特徴量の分布
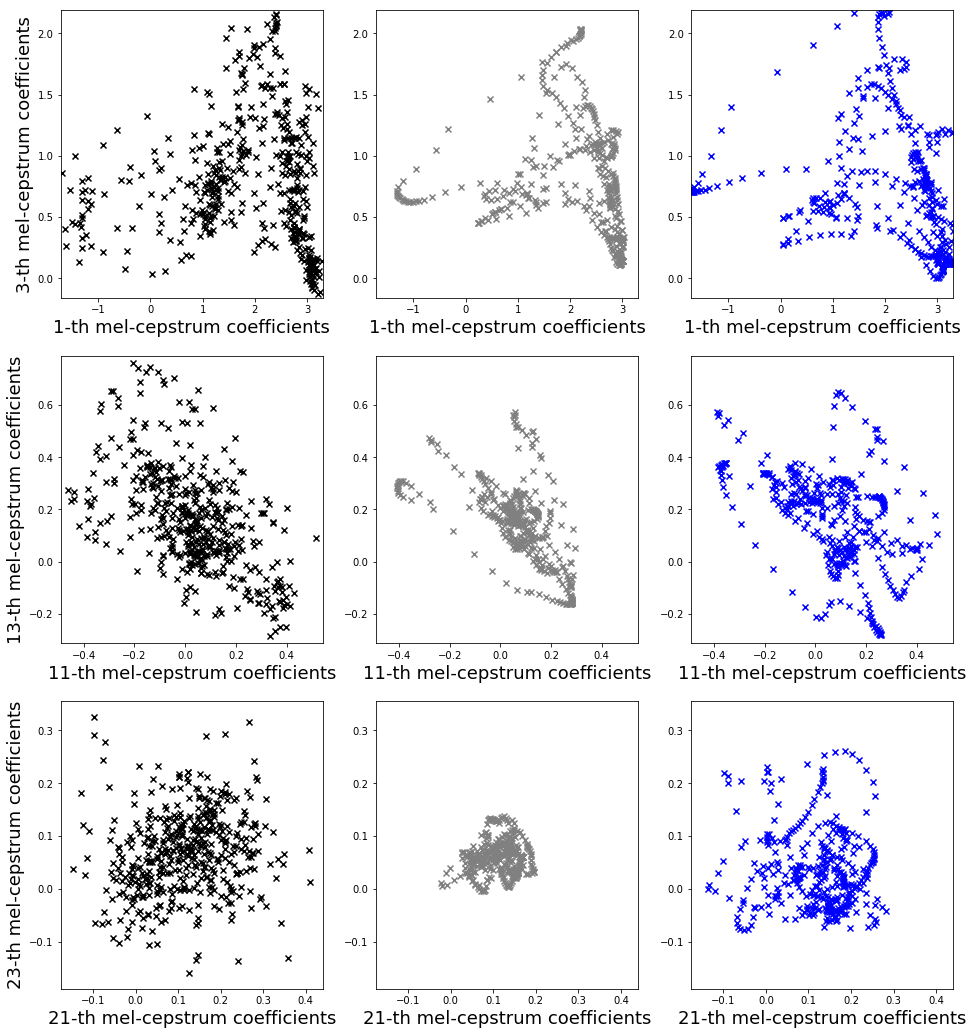
arctic_b0537 の一発話に対して計算したものです。論文で示されているほど顕著ではない気がしますが、おおまかに同様の結果が得られました。
感想
- GANのチューニングは難しい。人力(直感)ハイパーパラメータのチューニングを試しましたが、大変でした。そしてあまりうまくできた自信がありません。潤沢な計算資源でなんとかしたい…
- GANの学習は不安定(に感じる)が、通常の MSE loss の学習は安定で、かつBidirectional LSTM RNNは安定してよいです(結果をここに貼っていなくて申し訳ですが)。ただし、計算にものすごく時間がかかるのと、GPUメモリをかなり使うので、とりあえず通常のfeed forward型で実験した結果をまとめました
- state-levelの継続長モデルに、GANを使うのはあまり上手くできませんでした。ここに貼ったサンプルからはわからないのですが(すいません)、GとDが上手く競い合わず、Dが勝ってしまう場合がほとんどでした(結果それが一番まし)。上手く競い合わせるようとすると、早口音声が生成されてしまったり、と失敗がありました。
- F0を ADV lossに加えると、より自然音声に近づくと感じる場合もあるが、一方でF0が不自然に揺れてしまう場合もありました。これはF0の抽出法、補間法にも依存するので、調査が必要です
- mgc, lf0, vuv, bapすべてで ADV lossに加えると、残念な結果を見ることになりました。理想的にはこれでも上手くいくと思って最初に試したのですが、だめでした。興味のある人はためしてみてください
- mgcの0次(パワー成分)は、ADV lossに加えない方がよい。考えてみると、特にフレーム単位のモデルの場合(RNNではなく)、パワー情報はnatural/generated の識別にはほとんど寄与しなさそうです。これはArxivの方の論文には書いていないのですが(僕の見逃しでなければ)、ASJの原稿 には書いてあるんですよね。一つのハマりどころでした
- DにRNNを使った実験も少しやってみたのですが、うまく競い合わせるのが難しそうでした。DにRNNを使うのは本質的には良いと思っているので、この辺りはもう少し色々試行錯誤したいと思っています
まとめ
GANの学習は大変でしたが、上手く学習できれば品質向上につながることを確認できました。今後、計算リソースが空き次第、RNNでの実験も進めようと思うのと、日本語でやってみようと思っています。
GANシリーズのその他記事へのリンクは以下の通りです。
参考
Arxivにあるペーパーだけでなく、その他いろいろ参考にしました。ありがとうございます。
- Yuki Saito, Shinnosuke Takamichi, Hiroshi Saruwatari, “Statistical Parametric Speech Synthesis Incorporating Generative Adversarial Networks”, arXiv:1709.08041 [cs.SD], Sep. 2017
- Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari, “Training algorithm to deceive anti-spoofing verification for DNN-based text-to-speech synthesis,” IPSJ SIG Technical Report, 2017-SLP-115, no. 1, pp. 1-6, Feb., 2017. (in Japanese)
- Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari, “Voice conversion using input-to-output highway networks,” IEICE Transactions on Information and Systems, Vol.E100-D, No.8, pp.1925–1928, Aug. 2017
- https://www.slideshare.net/ShinnosukeTakamichi/dnnantispoofing
- https://www.slideshare.net/YukiSaito8/Saito2017icassp
- https://github.com/SythonUK/whisperVC
- Yuki Saito, Shinnosuke Takamichi, and Hiroshi Saruwatari, “Experimental investigation of divergences in adversarial DNN-based speech synthesis,” Proc. ASJ, Spring meeting, 1-8-7, –, Sep., 2017. (in Japanese)
Ryuichi Yamamoto
Engineer/Researcher
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.