Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention. [arXiv:1710.08969]
Summary
三行まとめ
- arXiv:1710.08969: Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention. を読んで、実装しました
- RNNではなくCNNを使うのが肝で、オープンソースTacotronと同等以上の品質でありながら、高速に (一日程度で) 学習できる のが売りのようです。
- LJSpeech Dataset を使って、英語TTSモデルを作りました(学習時間一日くらい)。完全再現とまではいきませんが、大まかに論文の主張を確認できました。
前置き
本当は DeepVoice3 の実装をしていたのですが、どうも上手くいかなかったので気分を変えてやってみました。 以前 Tacotronに関する長いブログ記事 (リンク) を書いてしまったのですが、読む方も書く方もつらいので、簡潔にまとめることにしました。興味のある人は続きもどうぞ。
概要
End-to-endテキスト音声合成 (Text-to-speech synthesis; TTS) のための Attention付き畳み込みニューラルネット (CNN) が提案されています。SampleRNN, Char2Wav, Tacotronなどの従来提案されてきたRNNをベースとする方法では、モデルの構造上計算が並列化しにくく、 学習/推論に時間がかかることが問題としてありました。本論文では、主に以下の二つのアイデアによって、従来法より速く学習できるモデルを提案しています。
- RNNではなくCNNを使うこと (参考論文: arXiv:1705.03122)
- Attentionがmotonicになりやすくする効果を持つLossを考えること (Guided attention)
実験では、オープンソースTacotron (keithito/tacotron) の12日学習されたモデルと比較し、主観評価により同等以上の品質が得られたことが示されています。
DeepVoice3 との違い
ほぼ同時期に発表されたDeepVoice3も同じく、CNNをベースとするものです。論文を読みましたが、モチベーションとアプローチの基本は DeepVoice3 と同じに思いました。しかし、ネットワーク構造は DeepVoice3とは大きく異なります。いくつか提案法の特徴を挙げると、以下のとおりです。
- ネットワークが深い(DeepVoice3だとEncoder, Decoder, Converter それぞれ10未満ですが、この論文ではDecoderだけで20以上)。すべてにおいて深いです。カーネルサイズは3と小さいです1
- Fully-connected layer ではなく1x1 convolutionを使っています
- チャンネル数が大きい(256とか512とか、さらにネットワーク内で二倍になっていたりする)。DeepVoice3だとEncoderは64です
- レイヤーの深さに対して指数上に大きくなるDilationを使っています(DeepVoiceではすべてdilation=1)
- アテンションレイヤーは一つ(DeepVoice3は複数
DeepVoice3は、arXiv:1705.03122 のモデル構造とかなり似通っている一方で、本論文では(参考文献としてあげられていますが)影も形もないくらい変わっている、という印象を受けます。
ロスに関しては、Guided attentionに関するロスが加わるのに加えて、TacotronやDeepVoice3とは異なり、スペクトログラム/メルスペクトログラムに関して binary divergence (定義は論文参照) をロスに加えているという違いがあります。
実験
LJSpeech Dataset を使って、17時間くらい(26.5万ステップ)学習しました。計算資源の都合上、SSRNのチャンネル数は512ではなくその半分の256にしました。
なお、実装するにあたっては、厳密に再現しようとはせず、色々雰囲気でごまかしました。もともとDeepVoice3の実装をしていたのもあり、アイデアをいくつか借りています。例えば、デコーダの出力をいつ止めるか、というdone flag predictionをネットワークに入れています。Dropoutについて言及がありませんが、ないと汎化しにくい印象があったので2、足しました。
計算速度は、バッチサイズ16で、4.3 step/sec くらいの計算速度でした。僕のマシンのGPUはGTX 1080Ti です。使用したハイパーパラメータはこちらです。学習に使用したコマンドは以下です(メモ)。
python train.py --data-root=./data/ljspeech --checkpoint-dir=checkpoints_nyanko \
--hparams="use_preset=True,builder=nyanko" \
--log-event-path=log/nyanko_preset
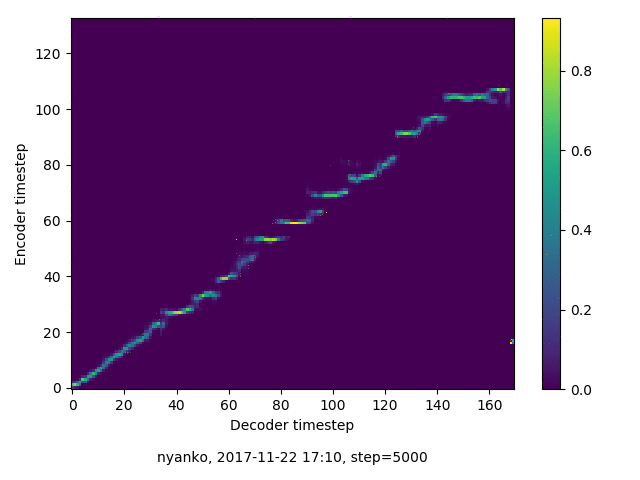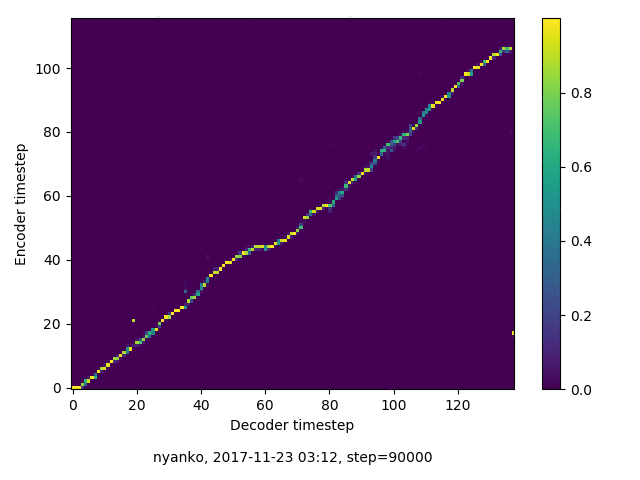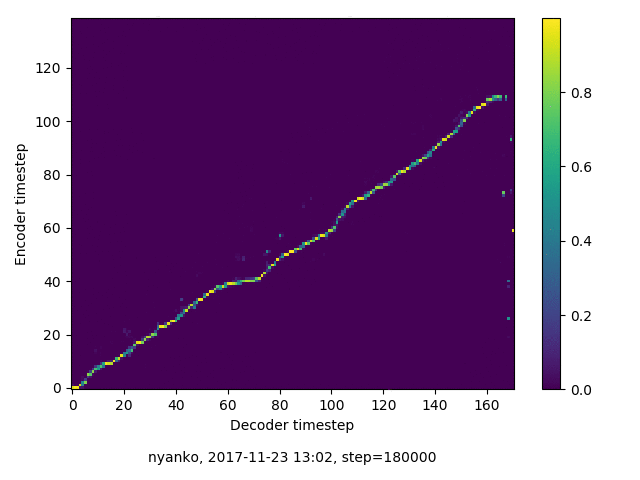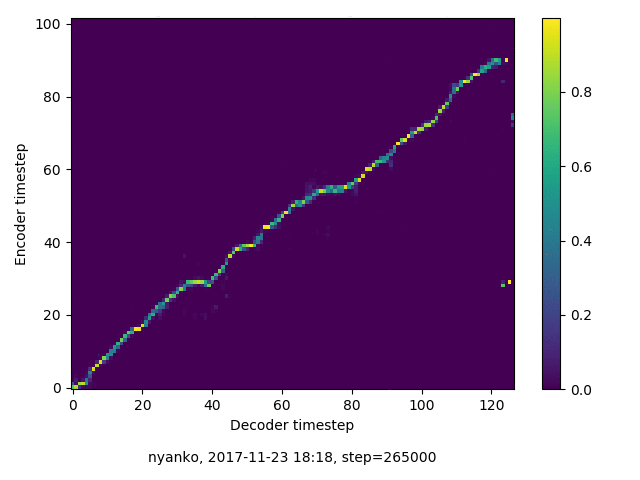
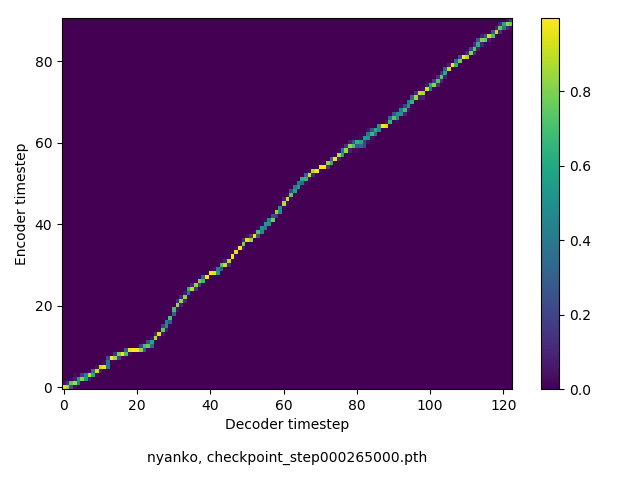
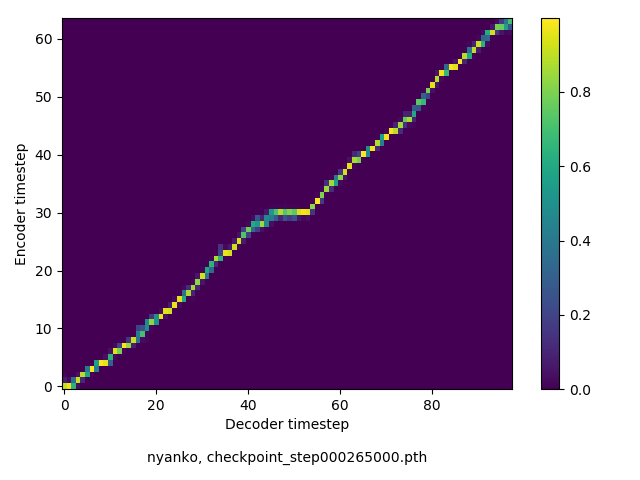
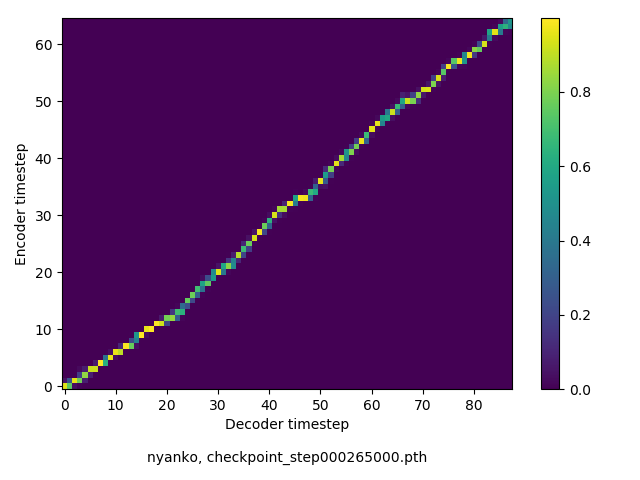
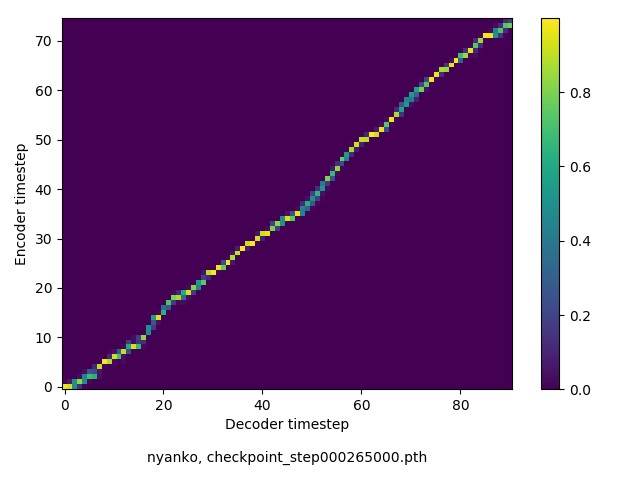
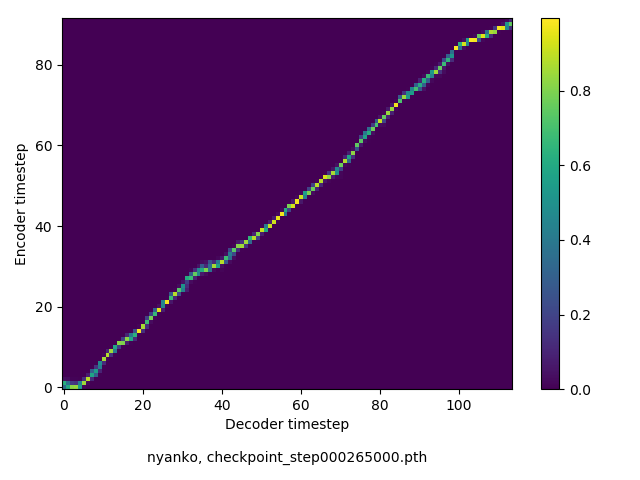
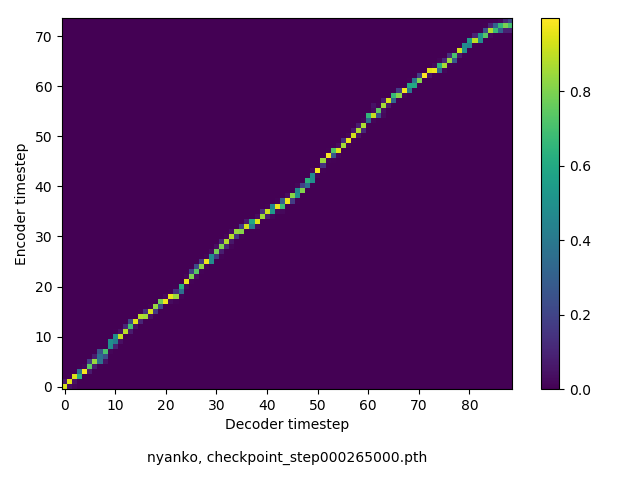
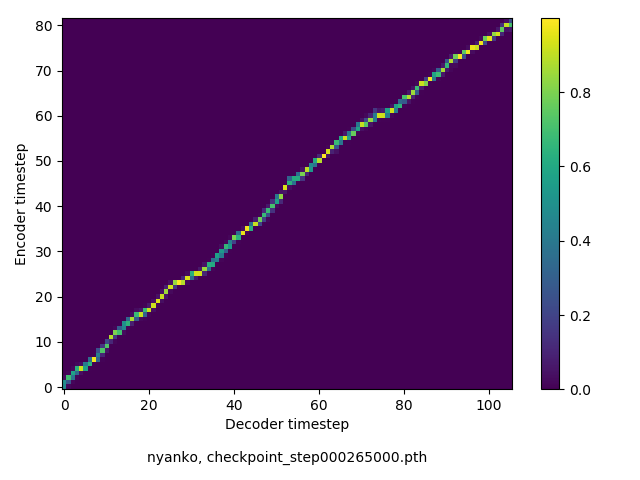
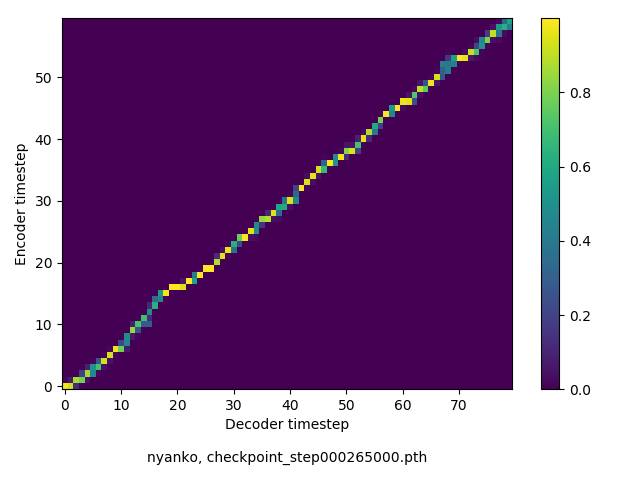
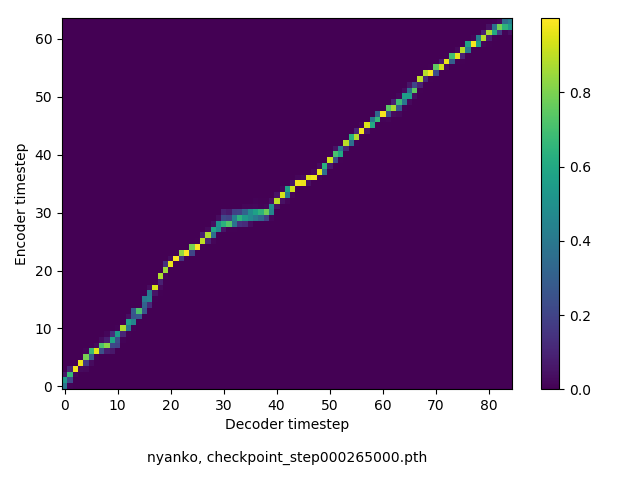
アライメントの学習過程
数万ステップで、綺麗にmonotonicになりました。GIFは、同じ音声に対するアライメントではなく、毎度違う(ランダムな)音声サンプルに対するアライメントを計算して、くっつけたものです(わかりずらくすいません
各種ロスの遷移
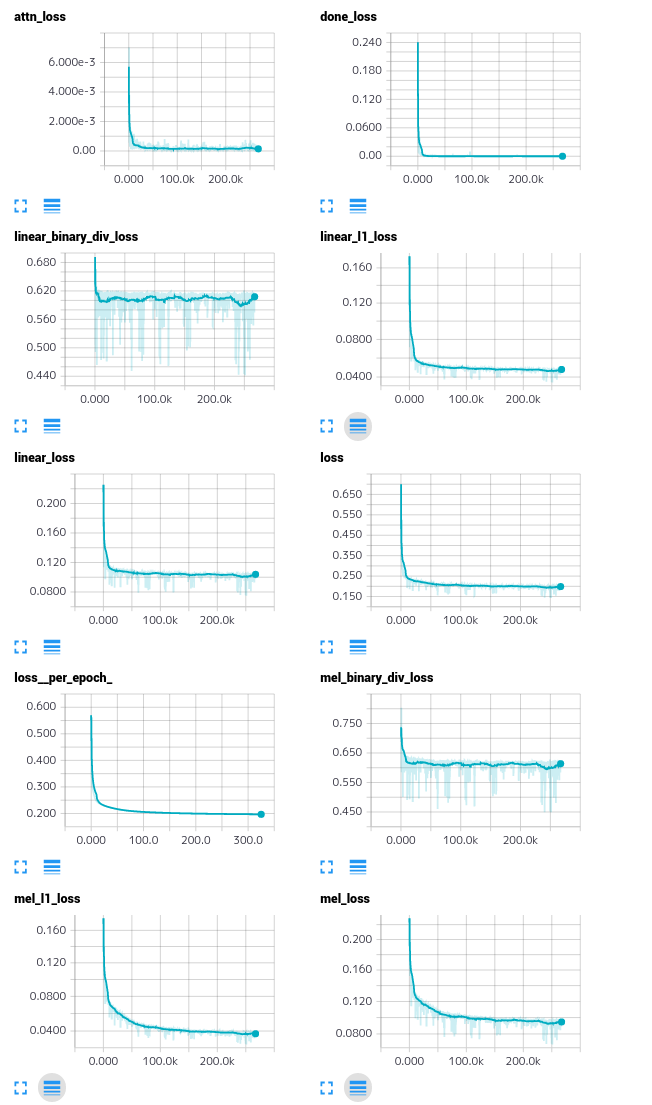
見づらくて申し訳ありませんという感じですが、僕のための簡易ログということで貼っておきます。binary divergenceは、すぐに収束したようでした。
音声サンプル
公式音声サンプル と同じ文章(抜粋)
公式サンプルとの比較です。11/23時点で、公式のサンプル数が15個と多いので、適当に3つ選びました。公式と比べると少し異なっている印象を受けますが、まぁまぁ良いかなと思いました(曖昧ですが
icassp stands for the international conference on acoustics, speech and signal processing.
(90 chars, 14 words)
a matrix is positive definite, if all eigenvalues are positive.
(63 chars, 12 words)
a spectrogram is obtained by applying es-tee-ef-tee to a signal.
(64 chars, 11 words)
keithito/tacotron のサンプル と同じ文章
Scientists at the CERN laboratory say they have discovered a new particle.
(74 chars, 13 words)
There’s a way to measure the acute emotional intelligence that has never gone out of style.
(91 chars, 18 words)
President Trump met with other leaders at the Group of 20 conference.
(69 chars, 13 words)
The Senate’s bill to repeal and replace the Affordable Care Act is now imperiled.
(81 chars, 16 words)
Generative adversarial network or variational auto-encoder.
(59 chars, 7 words)
The buses aren’t the problem, they actually provide a solution.
(63 chars, 13 words)
まとめ & わかったことなど
- Tacotronでは学習に何日もかかっていましたが(計算も遅く1日で10万step程度)、1日でそれなりの品質になりました。
- Guided atetntionがあると、確かに速くattentionがmonotonicになりました。
- 2時間程度の学習では ここ にあるのと同程度の品質にはなりませんでした…
- DeepVoice3のモデルアーキテクチャで学習した場合と比べると、品質は向上しました
- DeepVoice3と比べると、深いせいなのか学習が難しいように思いました。重みの初期化のパラメータをちょっといじると、sigmoidの出力が0 or 1になって学習が止まる、といったことがありました。重みの初期化はとても重要でした
- 上記にも関連して、勾配のノルムが爆発的に大きくなることがしばしばあり、クリッピングを入れました(重要でした)
- Binary divergenceをロスにいれても品質には影響がないように感じました。ただしないと学習初期に勾配が爆発しやすかったです
- 提案法は色々なアイデアが盛り込まれているのですが、実際のところどれが重要な要素なのか、といった点に関しては、論文では明らかにされていなかったように思います。今後その辺りを明らかにする論文があってもいいのではないかと思いました。
- 学習に使うGPUメモリ量、Tacotronより多い(SSRNのチャンネル数512, バッチサイズ16で
8GBくらい5~6GB くらいでした)……厳しい……3 - 2017/12/19追記: Dropoutなしだと、入力テキストとは無縁の英語らしき何かが生成されるようになってしまいました。Dropoutはやはり重要でした
一番の学びは、ネットワークの重みの初期化方法は重要、ということでした。おしまい
参考
- Hideyuki Tachibana, Katsuya Uenoyama, Shunsuke Aihara, “Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention”. arXiv:1710.08969, Oct 2017.
- Wei Ping, Kainan Peng, Andrew Gibiansky, et al, “Deep Voice 3: 2000-Speaker Neural Text-to-Speech”, arXiv:1710.07654, Oct. 2017.
- Jonas Gehring, Michael Auli, David Grangier, et al, “Convolutional Sequence to Sequence Learning”, arXiv:1705.03122, May 2017.
- He, Kaiming, et al. “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification.” Proceedings of the IEEE international conference on computer vision. 2015.
Ryuichi Yamamoto
Engineer/Researcher
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.