【108 話者編】Deep Voice 3: 2000-Speaker Neural Text-to-Speech / arXiv:1710.07654 [cs.SD]
Summary
- 論文リンク: arXiv:1710.07654
- コード: https://github.com/r9y9/deepvoice3_pytorch
- VCTK: https://datashare.ed.ac.uk/handle/10283/2950
- 音声サンプルまとめ: https://r9y9.github.io/deepvoice3_pytorch/
三行まとめ
- arXiv:1710.07654: Deep Voice 3: 2000-Speaker Neural Text-to-Speech を読んで、複数話者の場合のモデルを実装しました
- 論文のタイトル通りの2000話者とはいきませんが、VCTK を使って、108 話者対応の英語TTSモデルを作りました(学習時間1日くらい)
- 入力する話者IDを変えることで、一つのモデルでバリエーションに富んだ音声サンプルを生成できることを確認しました
概要
【単一話者編】Deep Voice 3: 2000-Speaker Neural Text-to-Speech / arXiv:1710.07654 [cs.SD] の続編です。
論文概要は前回紹介したものと同じなので、話者の条件付けの部分についてのみ簡単に述べます。なお、話者の条件付けに関しては、DeepVoice2の論文 (arXiv:1705.08947 [cs.CL]) の方が詳しいです。
まず基本的に、話者の情報は trainable embedding としてモデルに組み込みます。text embeddingのうようにネットワークの入力の一箇所に入れるような設計では学習が上手くかない(話者情報を無視するようになってしまうのだと思います)ため、ネットワークのあらゆるところに入れるのがポイントのようです。具体的には、Encoder, Decoder (+ Attention), Converterのすべてに入れます。さらに具体的には、ネットワークの基本要素である Gated linear unit + Conv1d のすべてに入れます。詳細は論文に記載のarchitectureの図を参照してください。
話者の条件付けに関して、一つ注意を加えるとすれば、本論文には明示的に書かれていませんが、 speaker embeddingは各時間stepすべてにexpandして用いるのだと思います(でないと実装するときに困る)。DeepVoice2の論文にはその旨が明示的に書かれています。
VCTK の前処理
実験に入る前に、VCTKの前処理について、簡単にまとめたいと思います。VCTKの音声データには、数秒に渡る無音区間がそれなりに入っているので、それを取り除く必要があります。以前、日本語 End-to-end 音声合成に使えるコーパス JSUT の前処理 で書いた内容と同じように、音素アライメントを取って無音区間を除去します。僕は以下の二つの方法をためしました。
論文中には、(無音除去のため、という文脈ではないのですが1)Gentleを使った旨が書かれています。しかし、試したところアライメントが失敗するケースがそれなりにあり、loop は後者の方法を用いており良い結果も出ていることから、結論としては僕は後者を採用しました。なお、両方のコードは残してあるので、気になる方は両方ためしてみてください。
実験
VCTK の108話者分のすべて2を使用して、20時間くらい(30万ステップ x 2)学習しました。30万ステップ学習した後できたモデルをベースに、さらに30万ステップ学習しました3。モデルは、単一話者の場合とほとんど同じですが、変更を加えた点を以下にまとめます。
- 共通: Speaker embedding を追加しました。
- 共通: Speaker embeddingをすべての時間ステップにexpandしたあと、Dropoutを適用するようにしました(論文には書いていませんが、結論から言えば重要でした…)
- Decoder: アテンションのレイヤー数を2から1に減らしました
計算速度は、バッチサイズ16で、8.6 step/sec くらいでした。GPUメモリの使用量は9GB程度でした。Convolution BlockごとにLinearレイヤーが追加されるので、それなりにメモリ使用量が増えます。PyTorch v0.3.0を使いました。
学習に使用したコマンドは以下です。
python train.py --data-root=./data/vctk --checkpoint-dir=checkpoints_vctk \
--hparams="preset=deepvoice3_vctk,builder=deepvoice3_multispeaker" \
--log-event-path=log/deepvoice3_multispeaker_vctk_preset \
--load-embedding=20171221_deepvoice3_checkpoint_step000300000.pth
# << 30万ステップで一旦打ち切り >>
# もう一度0から30万ステップまで学習しなおし
python train.py --data-root=./data/vctk --checkpoint-dir=checkpoints_vctk_fineturn \
--hparams="preset=deepvoice3_vctk,builder=deepvoice3_multispeaker" \
--log-event-path=log/deepvoice3_multispeaker_vctk_preset_fine \
--restore-parts=./checkpoints_vctk/checkpont_step000300000.pth
学習を高速化するため、LJSpeechで30万ステップ学習したモデルのembeddingの部分を再利用しました。また、cyclic annealingのような効果が得られることを期待して、一度学習を打ち切って、さらに0stepからファインチューニングしてみました。
コードのコミットハッシュは 0421749 です。正確なハイパーパラメータが知りたい場合は、ここから辿れると思います。
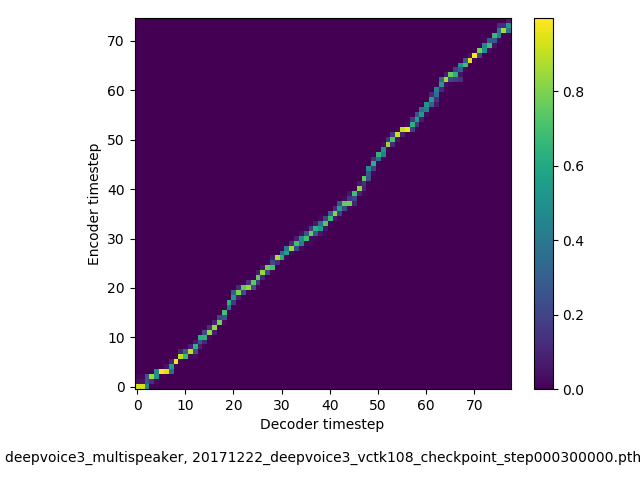
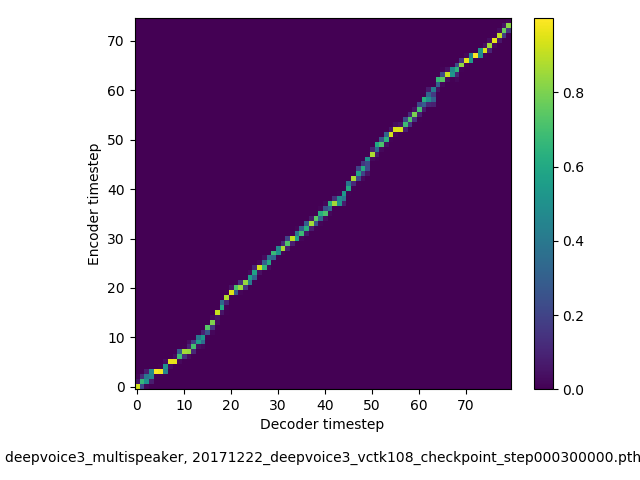
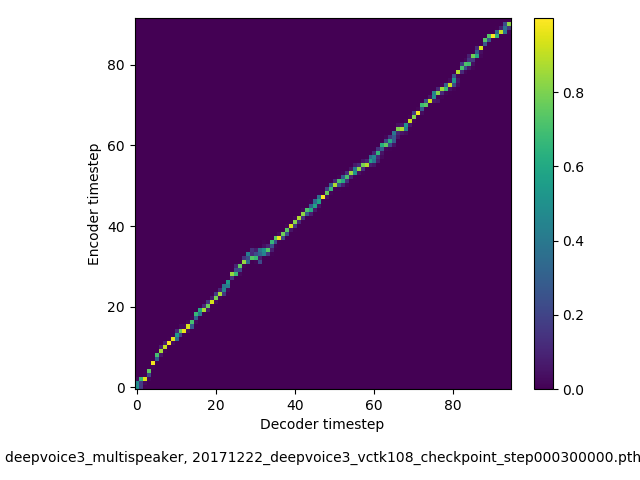
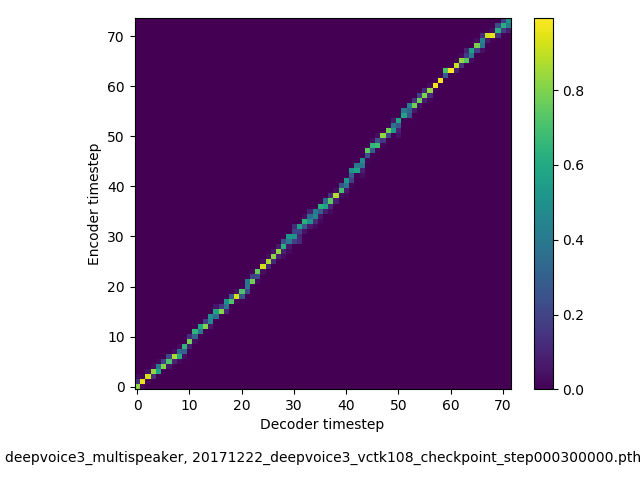
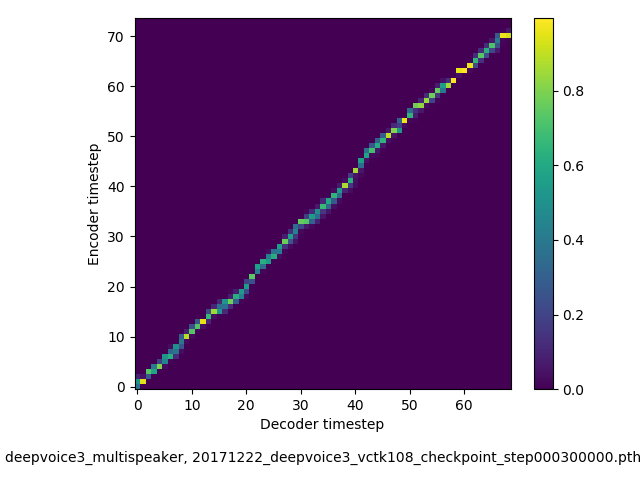
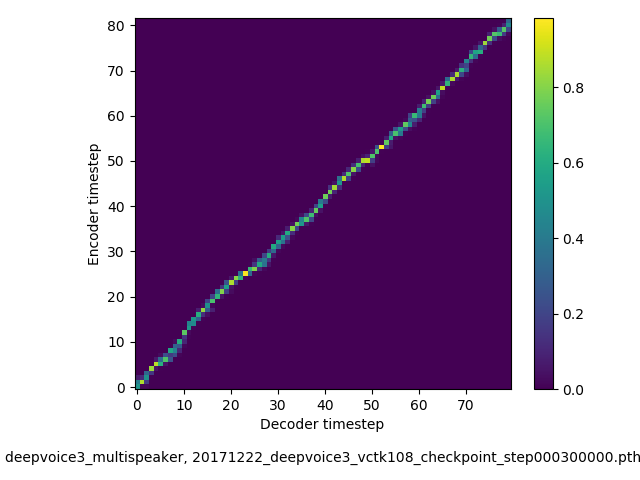
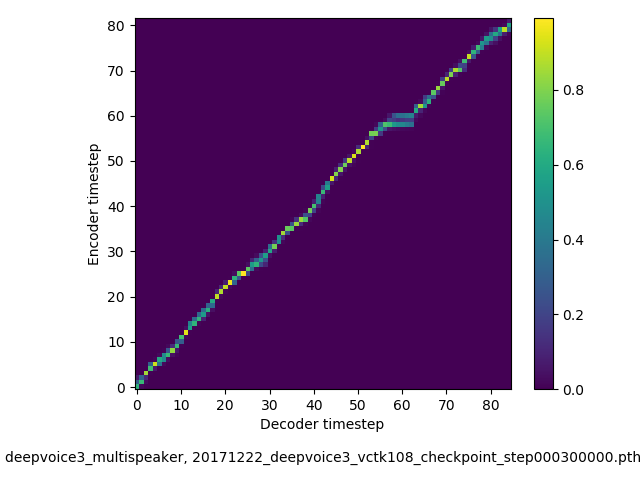
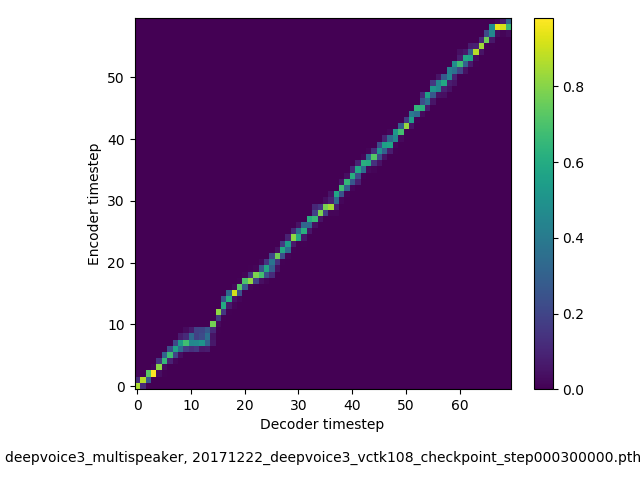
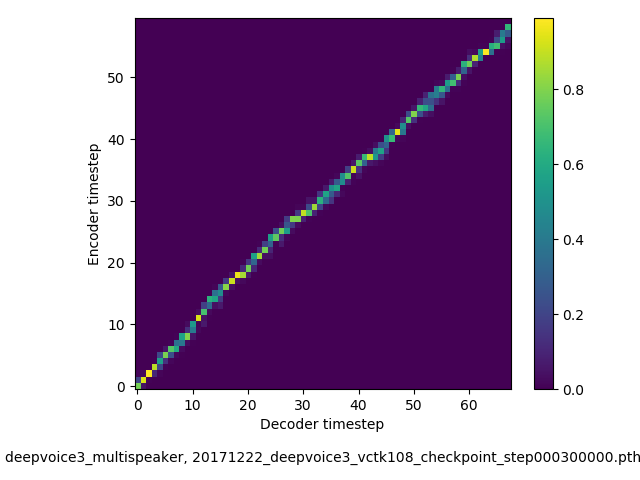
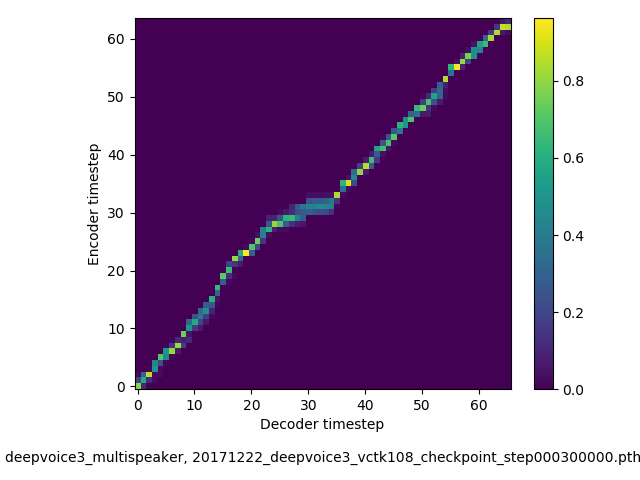
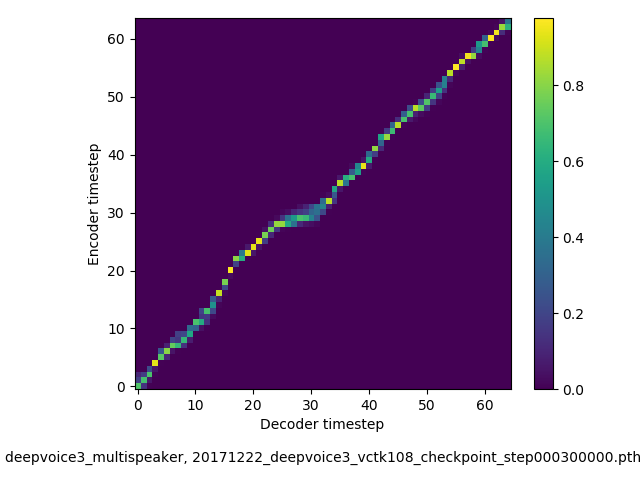
アライメントの学習過程 (~30万ステップ)
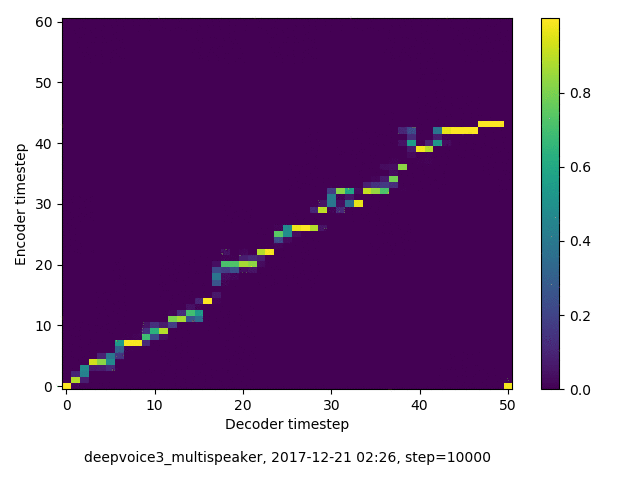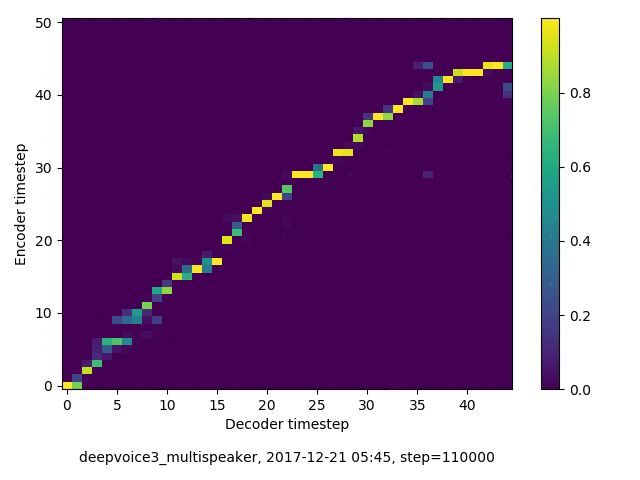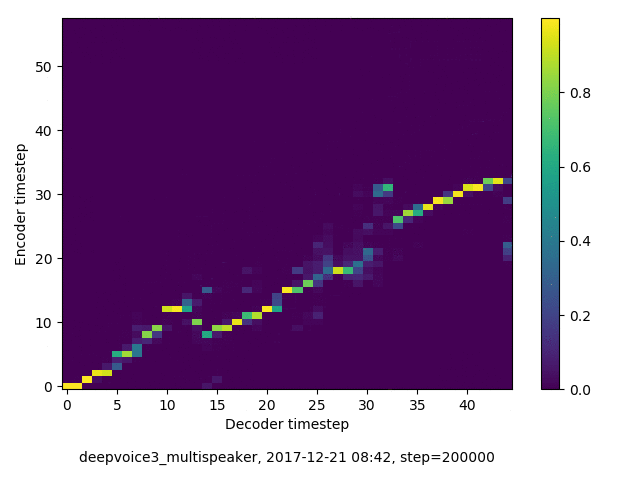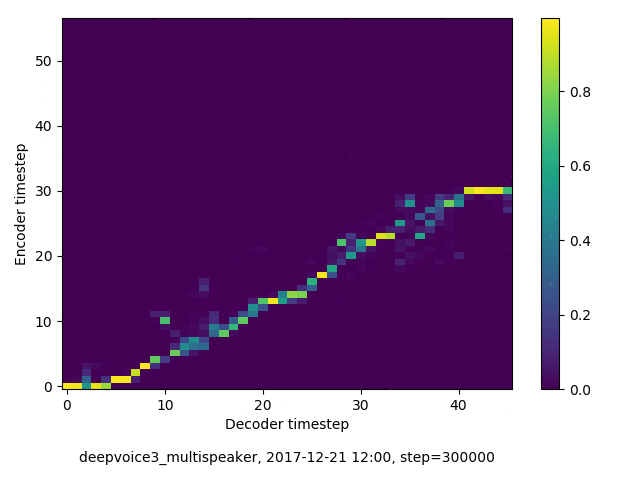
学習された Speaker embedding の可視化
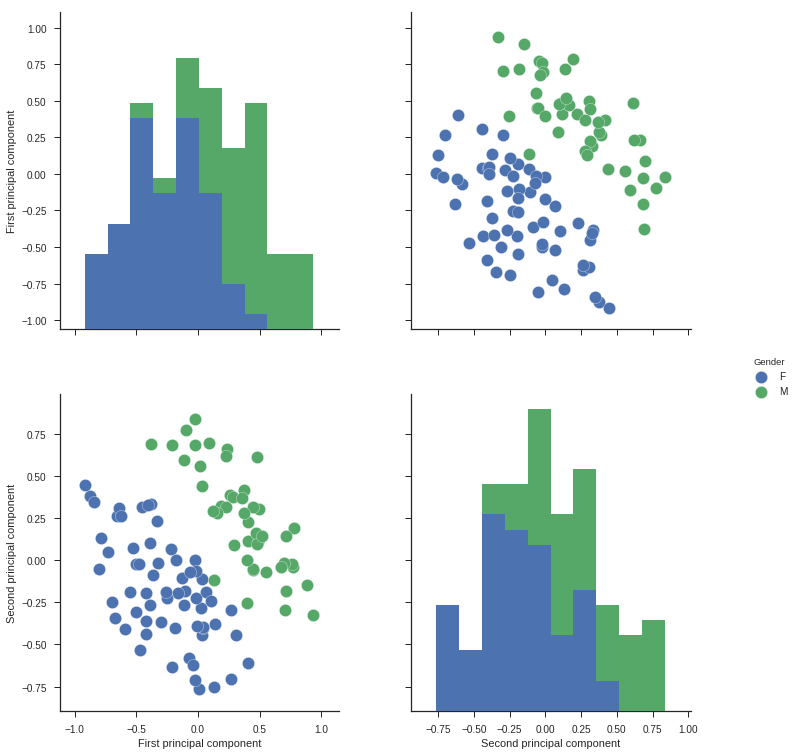
論文のappendixに書かれているのと同じように、学習されたEmbeddingに対してPCAをかけて可視化しました。論文の図とは少々異なりますが、期待通り、男女はほぼ線形分離できるようになっていることは確認できました。
音声サンプル
最初に僕の感想を述べておくと、LJSpeechで単一話者モデルを学習した場合と比べると、汎化しにくい印象がありました。文字がスキップされるといったエラーケースも比較して多いように思いました。 たくさんサンプルを貼るのは大変なので、興味のある方は自分で適当な未知テキストを与えて合成してみてください。学習済みモデルは deepvoice3_pytorch#pretrained-models からダウンロードできるようにしてあります。
Loop と同じ文章
Some have accepted this as a miracle without any physical explanation
(69 chars, 11 words)
speaker IDが若い順に12サンプルの話者ID を与えて、合成した結果を貼っておきます。
225, 23, F, English, Southern, England (ID, AGE, GENDER, ACCENTS, REGION)
226, 22, M, English, Surrey
227, 38, M, English, Cumbria
228, 22, F, English, Southern England
229, 23, F, English, Southern England
230, 22, F, English, Stockton-on-tees
231, 23, F, English, Southern England
232, 23, M, English, Southern England
233, 23, F, English, Staffordshire
234, 22, F, Scottish, West Dumfries
236, 23, F, English, Manchester
237, 22, M, Scottish, Fife
声質だけでなく、話速にもバリエーションが出ているのがわかります。231 の最初で一部音が消えています(こういったエラーケースはよくあります)。
keithito/tacotron のサンプル と同じ文章
簡単に汎化性能をチェックするために、未知文章でテストします。
- 男性 (292, 23, M, NorthernIrish, Belfast)
- 女性 (288, 22, F, Irish, Dublin)
の二つのサンプルを貼っておきます。
Scientists at the CERN laboratory say they have discovered a new particle.
(74 chars, 13 words)
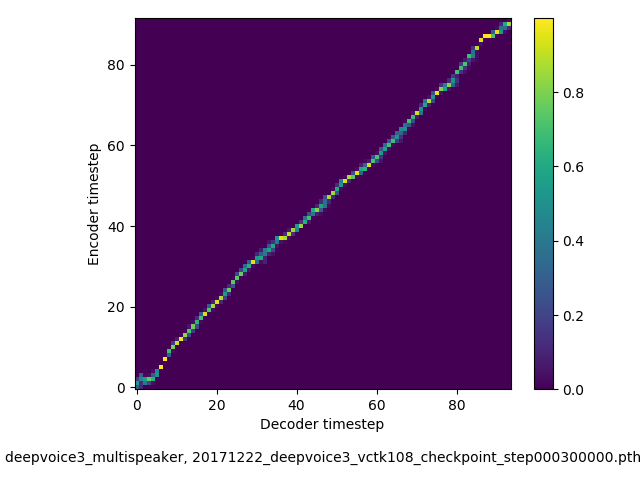
There’s a way to measure the acute emotional intelligence that has never gone out of style.
(91 chars, 18 words)
President Trump met with other leaders at the Group of 20 conference.
(69 chars, 13 words)
The Senate’s bill to repeal and replace the Affordable Care Act is now imperiled.
(81 chars, 16 words)
Generative adversarial network or variational auto-encoder.
(59 chars, 7 words)
The buses aren’t the problem, they actually provide a solution.
(63 chars, 13 words)
ところどころ音が抜けているのが目立ちます。色々実験しましたが、やはり単一話者 24hのデータで学習したモデルに比べると、一話者あたり30分~1h程度のデータでは、汎化させるのが難しい印象を持ちました。
まとめ
- 複数話者版のDeepVoice3を実装して、実際に108話者のデータセットで学習し、それなりに動くことを確認できました
- 複数話者版のDeepVoice3では、アテンションの学習が単一話者の場合と比べて難しい印象でした。アテンションレイヤーの数を2から1に減らすと、アライメントがくっきりする傾向にあることを確認しました。
- VCTKの前処理大事、きちんとしましょう
- Speaker embedding にDropoutをかけるのは、論文には記載されていませんが、結果から言って重要でした。ないと、音声の品質以前の問題として、文字が正しく発音されない、といった現象に遭遇しました。
- Speaker embedding をすべての時刻に同一の値をexpandしてしまうと過学習しやすいのではないかいう予測を元に、各時刻でランダム性をいれることでその問題を緩和できないかと考え、Dropoutを足してみました。上手く言ったように思います
- 論文の内容について詳しく触れていませんが、実はけっこう雑というか、文章と図に不一致があったりします(例えば図1にあるEncoder PreNet/PostNet は文章中で説明がない)。著者に連絡して確認するのが一番良いのですが、どういうモデルなら上手くいくか考えて試行錯誤するのも楽しいので、今回は雰囲気で実装しました。それなりに上手く動いているように思います
次は、DeepVoice3、Tacotron 2 (arXiv:1712.05884 [cs.CL]) で有効性が示されている WaveNet Vocoder を実装して、品質を改善してみようと思っています。
参考
- Wei Ping, Kainan Peng, Andrew Gibiansky, et al, “Deep Voice 3: 2000-Speaker Neural Text-to-Speech”, arXiv:1710.07654, Oct. 2017.
- Sercan Arik, Gregory Diamos, Andrew Gibiansky,, et al, “Deep Voice 2: Multi-Speaker Neural Text-to-Speech”, arXiv:1705.08947, May 2017.
- Jonathan Shen, Ruoming Pang, Ron J. Weiss, et al, “Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions”, arXiv:1712.05884, Dec 2017.
関連記事
Ryuichi Yamamoto
Engineer/Researcher
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.