統計的声質変換クッソムズすぎワロタ(チュートリアル編)
はじめに
こんばんは。統計的声質変換(以降、簡単に声質変換と書きます)って面白いなーと思っているのですが、興味を持つ人が増えたらいいなと思い、今回は簡単なチュートリアルを書いてみます。間違っている箇所があれば、指摘してもらえると助かります。よろしくどうぞ。
前回の記事(統計的声質変換クッソムズすぎワロタ(実装の話) - LESS IS MORE)では変換部分のコードのみを貼りましたが、今回はすべてのコードを公開します。なので、記事内で示す声質変換の結果を、この記事を読んでいる方が再現することも可能です。対象読者は、特に初学者の方で、声質変換を始めたいけれど論文からコードに落とすにはハードルが高いし、コードを動かしながら仕組みを理解していきたい、という方を想定しています。役に立てば幸いです。
コード
https://github.com/r9y9/VoiceConversion.jl
Julia という言語で書かれています。Juliaがどんな言語かをさっと知るのには、以下のスライドがお勧めです。人それぞれ好きな言語で書けばいいと思いますが、個人的にJuliaで書くことになった経緯は、最後の方に簡単にまとめました。
サードパーティライブラリ
声質変換は多くのコンポーネントによって成り立っていますが、すべてを自分で書くのは現実的ではありません。僕は、主に以下のライブラリを活用しています。
- WORLD - 音声分析合成のフレームワークとして、あるいは単にスペクトル包絡を抽出するツールとして使っています。Juliaラッパーを書きました。
- SPTK - メル対数スペクトル近似(Mel-Log Spectrum Approximation; MLSA)フィルタを変換処理に使っています。これもJuliaラッパーを書きました。
- sklearn - sklearn.mixture をGMMの学習に使っています。pythonのライブラリは、juliaから簡単に呼べます。
音声分析合成に関しては、アカデミック界隈ではよく使われているSTRAIGHTがありますが、WORLDの方がライセンスもゆるくソースも公開されていて、かつ性能も劣らない(正確な話は、森勢先生の論文を参照してください)ので、おすすめです。
VoiceConversion.jl でできること
追記 2015/01/07
この記事を書いた段階のv0.0.1は、依存ライブラリの変更のため、現在は動きません。すみません。何のためのタグだ、という気がしてきますが、、最低限masterは動作するようにしますので、そちらをお試しください(基本的には、新しいコードの方が改善されています)。それでも動かないときは、issueを投げてください。
2014/11/10現在(v0.0.1のタグを付けました)、できることは以下の通りです(外部ライブラリを叩いているものを含む)。
- 音声波形からのメルケプストラムの抽出
- DPマッチングによるパラレルデータの作成
- GMMの学習
- GMMベースのframe-by-frame特徴量変換
- GMMベースのtrajectory特徴量変換
- GMMベースのtrajectory特徴量変換(GV考慮版)
- 音声分析合成系WORLDを使った声質変換
- MLSAフィルタを使った差分スペクトルに基づく声質変換
これらのうち、trajectory変換以外を紹介します。
チュートリアル:CMU_ARCTICを使ったGMMベースの声質変換(特徴抽出からパラレルデータの作成、GMMの学習、変換・合成処理まで)
データセットにCMU_ARCTICを使って、GMMベースの声質変換(clb -> slt)を行う方法を説明します。なお、VoiceConversion.jl のv0.0.1を使います。ubuntuで主に動作確認をしていますが、macでも動くと思います。
0. 前準備
0.1. データセットのダウンロード
Festvox: CMU_ARCTIC Databases を使います。コマンド一発ですべてダウンロードするスクリプトを書いたので、ご自由にどうぞ。
0.2. juliaのインストール
公式サイトからバイナリをダウンロードするか、githubのリポジトリをクローンしてビルドしてください。バージョンは、現在の最新安定版のv0.3.2を使います。
記事内では、juliaの基本的な使い方については解説しないので、前もってある程度調べておいてもらえると、スムーズに読み進められるかと思います。
0.3. VoiceConversion.jl のインストール
juliaを起動して、以下のコマンドを実行してください。
julia> Pkg.clone("https://github.com/r9y9/VoiceConversion.jl")
julia> Pkg.build("VoiceConversion")
サードパーティライブラリは、sklearnを除いてすべて自動でインストールされます。sklearnは、例えば以下のようにしてインストールしておいてください。
sudo pip install sklearn
これで準備は完了です!
1. 音声波形からのメルケプストラムの抽出
まずは、音声から声質変換に用いる特徴量を抽出します。特徴量としては、声質変換や音声合成の分野で広く使われているメルケプストラムを使います。メルケプストラムの抽出は、scripts/mcep.jl を使うことでできます。
2014/11/15 追記
実行前に、julia> Pkg.add("WAV") として、WAVパッケージをインストールしておいてください。(2014/11/15時点のmasterでは自動でインストールされますが、v0.0.1ではインストールされません、すいません)。また、メルケプストラムの出力先ディレクトリは事前に作成しておいてください(最新のスクリプトでは自動で作成されます)。
以下のようにして、2話者分の特徴量を抽出しましょう。以下のスクリプトでは、 ~/data/cmu_arctic/ にデータがあることを前提としています。
# clb
julia mcep.jl ~/data/cmu_arctic/cmu_us_clb_arctic/wav/ ~/data/cmu_arctic_jld/speakers/clb/
# slt
julia mcep.jl ~/data/cmu_arctic/cmu_us_slt_arctic/wav/ ~/data/cmu_arctic_jld/speakers/slt/
基本的な使い方は、mcep.jl <wavファイルがあるディレクトリ> <メルケプストラムが出力されるディレクトリ> になっています。オプションについては、 mcep.jl -h としてヘルプを見るか、コードを直接見てください。
抽出されたメルケプストラムは、HDF5フォーマットで保存されます。メルケプストラムの中身を見てみると、以下のような感じです。可視化には、PyPlotパッケージが必要です。Juliaを開いて、julia> Pkg.add("PyPlot") とすればOKです。IJuliaを使いたい場合(僕は使っています)は、julia> Pkg.add("IJulia") としてIJuliaもインストールしておきましょう。
# メルケプストラムの可視化
using HDF5, JLD, PyPlot
x = load("clb/arctic_a0028.jld")
figure(figsize=(16, 6), dpi=80, facecolor="w", edgecolor="k")
imshow(x["feature_matrix"], origin="lower", aspect="auto")
colorbar()
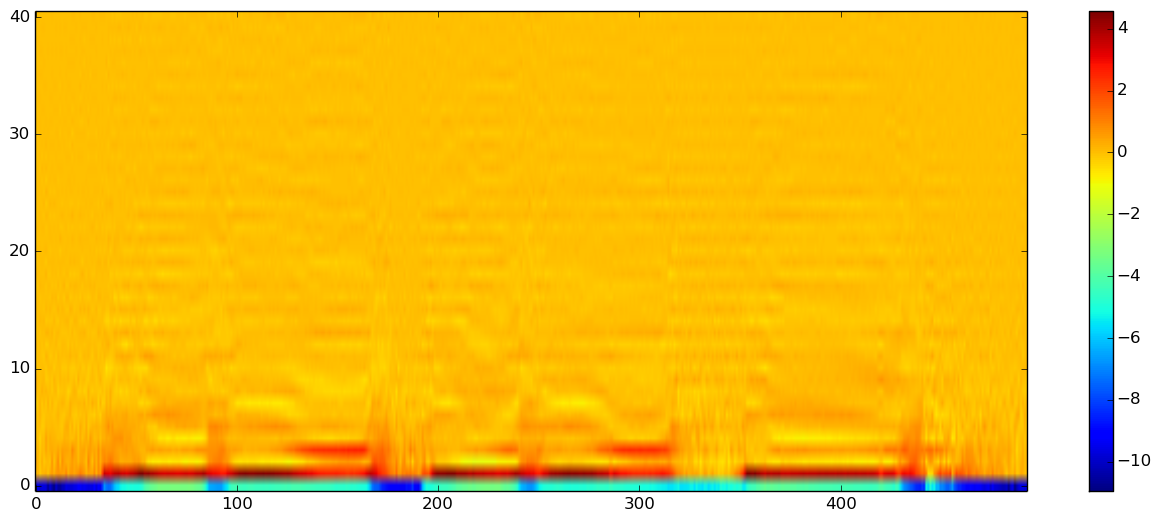
0次成分だけ取り出してみると、以下のようになります。
# メルケプストラムの0次成分のみを可視化
figure(figsize=(16, 6), dpi=80, facecolor="w", edgecolor="k")
plot(vec(x["feature_matrix"][1,:]), linewidth=2.0, label="0th order mel-cesptrum of clb_a0028")
xlim(0, size(x["feature_matrix"], 2)-10) # 末尾がsilenceだった都合上…(決め打ち)
xlabel("Frame")
legend(loc="upper right")
ylim(-10, -2) # 見やすいように適当に決めました
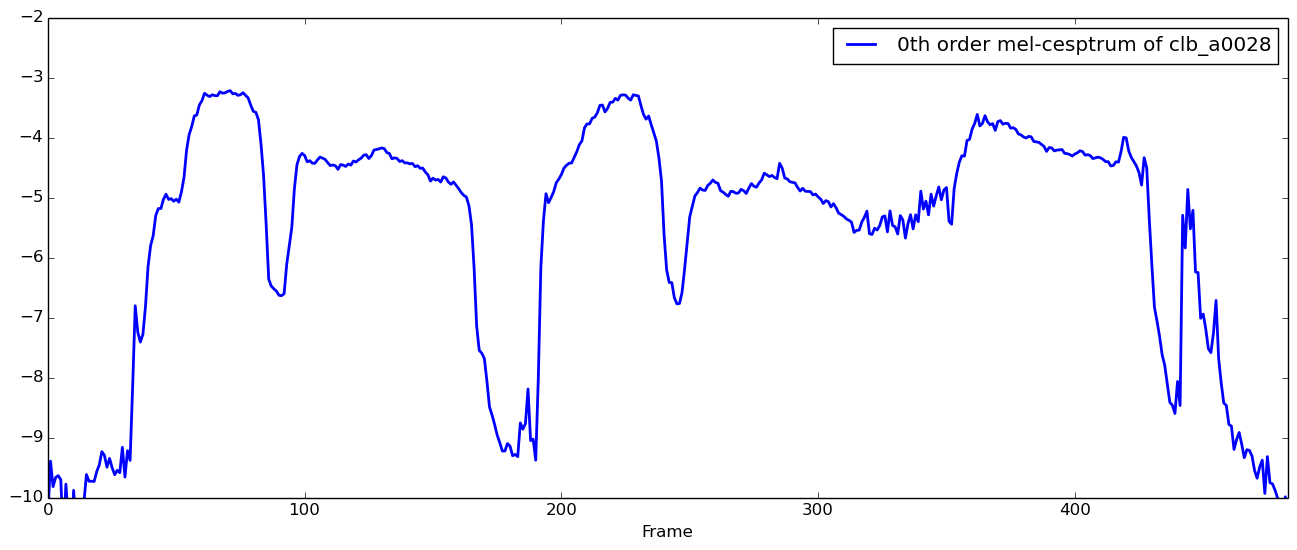
こんな感じです。話者clbのclb_a0028.wavを聞きながら、特徴量見てみてください。0次の成分からは、音量の大小が読み取れると思います。
2. DPマッチングによるパラレルデータの作成
次に、2話者分の特徴量を時間同期して連結します。基本的に声質変換では、音韻の違いによらない特徴量(非言語情報)の対応関係を学習するために、同一発話内容の特徴量を時間同期し(音韻の違いによる変動を可能な限りなくすため)、学習データとして用います。このデータのことを、パラレルデータと呼びます。
パラレルデータの作成には、DPマッチングを使うのが一般的です。scripts/align.jl を使うとできます。
julia align.jl ~/data/cmu_arctic_jld/speakers/clb ~/data/cmu_arctic_jld/speakers/slt ~/data/cmu_arctic_jld/parallel/clb_and_slt/
使い方は、align.jl <話者1(clb)の特徴量のパス> <話者2(slt)の特徴量のパス> <パラレルデータの出力先> になっています。
きちんと時間同期されているかどうか、0次成分を見て確認してみましょう。
時間同期を取る前のメルケプストラムを以下に示します。
# 時間同期前のメルケプストラム(0次)を可視化
x = load("clb/arctic_a0028.jld")
y = load("slt/arctic_a0028.jld")
figure(figsize=(16, 6), dpi=80, facecolor="w", edgecolor="k")
plot(vec(x["feature_matrix"][1,:]), linewidth=2.0, label="0th order mel-cesptrum of clb_a0028")
plot(vec(y["feature_matrix"][1,:]), linewidth=2.0, label="0th order mel-cesptrum of slt_a0028")
xlim(0, min(size(x["feature_matrix"], 2), size(y["feature_matrix"], 2))-10) # 決め打ち
xlabel("Frame")
legend(loc="upper right")
ylim(-10, -2) # 決め打ち
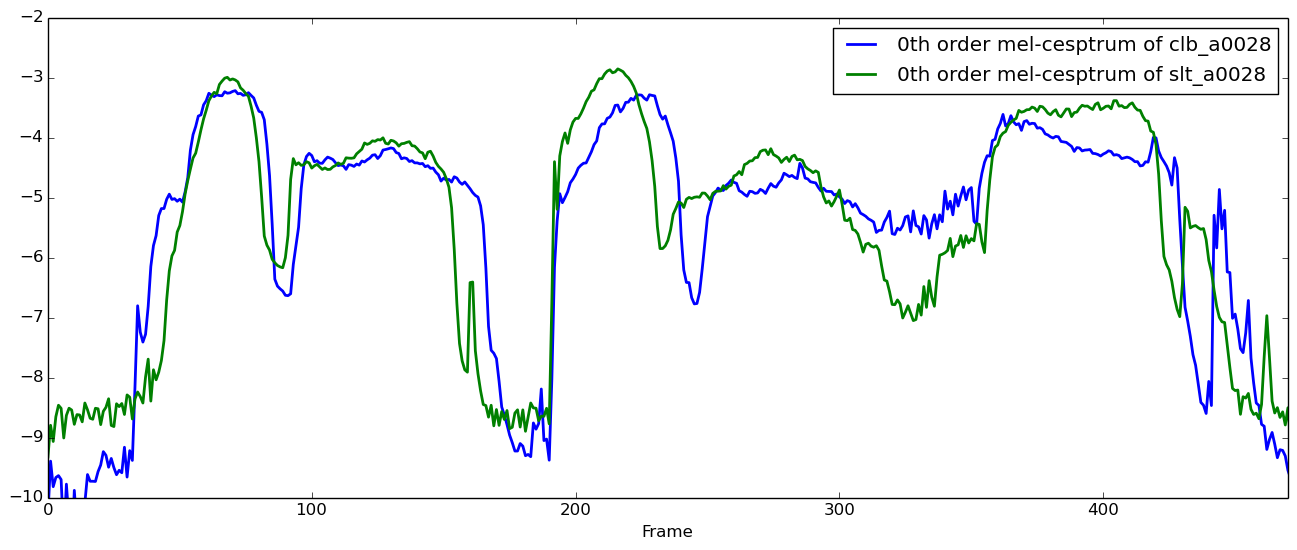
ちょっとずれてますね
次に、時間同期後のメルケプストラムを示します。
# 時間同期後のメルケプストラム(0次)を可視化
parallel = load("arctic_a0028_parallel.jld")
figure(figsize=(16, 6), dpi=80, facecolor="w", edgecolor="k")
plot(vec(parallel["src"]["feature_matrix"][1,:]), linewidth=2.0, "b", label="0th order mel-cesptrum of clb_a0028")
plot(vec(parallel["tgt"]["feature_matrix"][1,:]), linewidth=2.0, "g", label="0th order mel-cesptrum of slt_a0028")
xlim(0, size(parallel["tgt"]["feature_matrix"], 2))
xlabel("Frame")
legend()
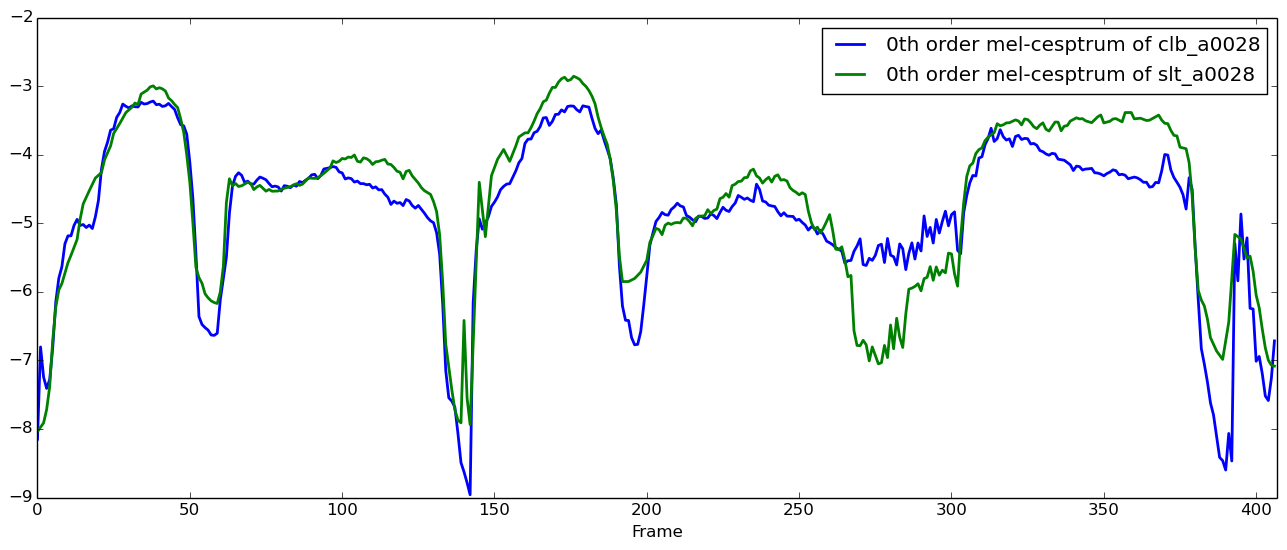
ずれが修正されているのがわかりますね。注意として、align.jl の中身を追えばわかるのですが、無音区間をしきい値判定で検出して、パラレルデータから除外しています。
結果、時間同期されたパラレルデータは以下のようになります。
# パラレルデータの可視化
figure(figsize=(16, 6), dpi=80, facecolor="w", edgecolor="k")
imshow(vcat(parallel["src"]["feature_matrix"], parallel["tgt"]["feature_matrix"]), origin="lower", aspect="auto")
colorbar()
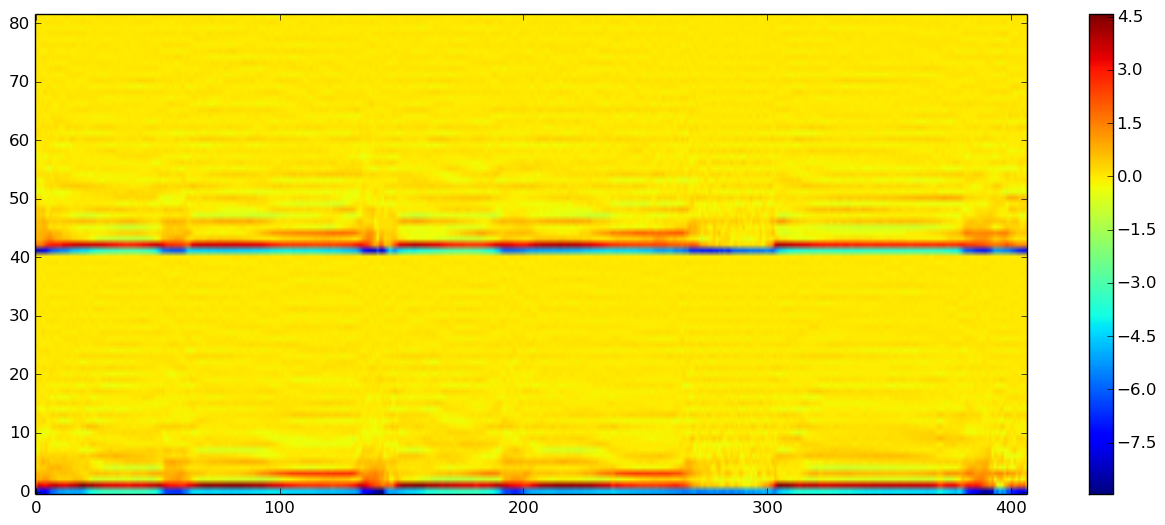
このパラレルデータを(複数の発話分さらに結合して)使って、特徴量の対応関係を学習していきます。モデルには、GMMを使います。
3. GMMの学習
GMMの学習には、sklearn.mixture.GMM を使います。GMMは古典的な生成モデルで、実装は探せばたくさん見つかるので、既存の有用なライブラリを使えば十分です。(余談ですが、pythonのライブラリを簡単に呼べるのはjuliaの良いところの一つですね)
scripts/train_gmm.jl を使うと、モデルのダンプ、julia <-> python間のデータフォーマットの変換等、もろもろやってくれます。
julia train_gmm.jl ~/data/cmu_arctic_jld/parallel/clb_and_slt/ clb_and_slt_gmm32_order40.jld --max 200 --n_components 32 --n_iter=100 --n_init=1
使い方は、train_gmm.jl <パラレルデータのパス> <出力するモデルデータのパス> になっています。上の例では、学習に用いる発話数、GMMの混合数、反復回数等を指定しています。オプションの詳細はスクリプトをご覧ください。
僕の環境では、上記のコマンドを叩くと2時間くらいかかりました。学習が終わったところで、学習済みのモデルのパラメータを可視化してみましょう。
まずは平均を見てみます。
# GMMの平均ベクトルを(いくつか)可視化
gmm = load("clb_and_slt_gmm32_order40.jld")
figure(figsize=(16, 6), dpi=80, facecolor="w", edgecolor="k")
for k=1:3
plot(gmm["means"][:,k], linewidth=2.0, label="mean of mixture $k")
end
legend()
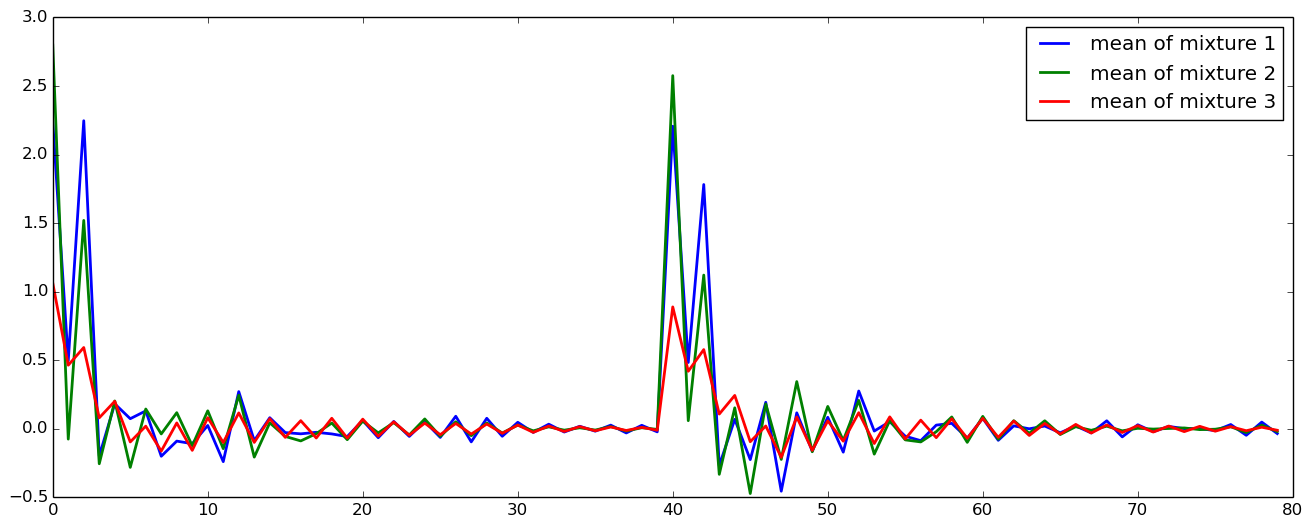
共分散の一部可視化してみると、以下のようになります。
# GMMの共分散行列を一部可視化
figure(figsize=(16, 6), dpi=80, facecolor="w", edgecolor="k")
imshow(gmm["covars"][:,:,2])
colorbar()
clim(0.0, 0.16)
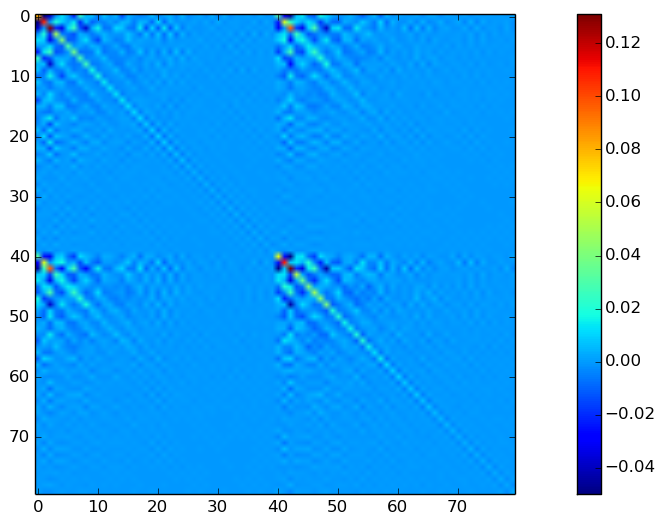
まぁこんなもんですね。
4. 音声分析合成WORLDを用いたGMMベースのframe-by-frame声質変換
さて、ようやく声質変換の準備が整いました。学習したモデルを使って、GMMベースのframe-by-frame声質変換(clb -> slt )をやってみましょう。具体的な変換アルゴリズムは、論文(例えば戸田先生のこれ)をチェックしてみてください。音声分析合成系にはWORLDを使います。
一般的な声質変換では、まず音声を以下の三つの成分に分解します。
- 基本周波数
- スペクトル包絡(今回いじりたい部分)
- 非周期性成分
その後、スペクトル包絡に対して変換を行い、変換後のパラメータを使って音声波形を合成するといったプロセスを取ります。これらは、scripts/vc.jl を使うと簡単にできるようになっています。本当にWORLDさまさまです。
julia vc.jl ~/data/cmu_arctic/cmu_us_clb_arctic/wav/arctic_a0028.wav clb_and_slt_gmm32_order40.jld clb_to_slt_a0028.wav --order 40
使い方は、vc.jl <変換対象の音声ファイル> <変換モデル> <出力wavファイル名> となっています。
上記のコマンドを実行すると、GMMベースのframe-by-frame声質変換の結果が音声ファイルに出力されます。以下に結果を貼っておくので、聞いてみてください。
変換元となる音声 clb_a0028
変換目標となる話者 slt_a0028
変換結果 clb_to_slt_a0028
話者性はなんとなく目標話者に近づいている気がしますが、音質が若干残念な感じですね。。
5. 差分スペクトル補正に基づく声質変換
最後に、より高品質な声質変換を達成可能な差分スペクトル補正に基づく声質変換を紹介します。差分スペクトル補正に基づく声質変換では、基本周波数や非周期性成分をいじれない代わりに音質はかなり改善します。以前書いた記事(統計的声質変換クッソムズすぎワロタ - LESS IS MORE)から、着想に関連する部分を引用します。
これまでは、音声を基本周波数、非周期性成分、スペクトル包絡に分解して、スペクトル包絡を表す特徴量を変換し、変換後の特徴量を元に波形を再合成していました。ただ、よくよく考えると、そもそも基本周波数、非周期性成分をいじる必要がない場合であれば、わざわざ分解して再合成する必要なくね?声質の部分のみ変換するようなフィルタかけてやればよくね?という考えが生まれます。実は、そういったアイデアに基づく素晴らしい手法があります。それが、差分スペクトル補正に基づく声質変換です。
差分スペクトル補正に基づく声質変換の詳細ついては、最近inter speechに論文が出たようなので、そちらをご覧ください。
こばくん、論文を宣伝しておきますね^^
5.1 差分特徴量の学習
さて、差分スペクトル補正に基づく声質変換行うには、変換元話者$X$と目標話者$Y$の特徴量の同時分布$P(X,Y)$を学習するのではなく、$P(X, Y-X)$ (日本語で書くとややこしいのですが、変換元話者の特徴量$X$と、変換元話者と目標話者の差分特徴量$Y-X$の同時分布)を学習します。これは、 train_gmm.jl を使ってGMMを学習する際に、--diff とオプションをつけるだけでできます。
julia train_gmm.jl ~/data/cmu_arctic_jld/parallel/clb_and_slt/ clb_to_slt_gmm32_order40_diff.jld --max 200 --n_components 32 --n_iter=100 --n_init=1 --diff
可視化してみます。
平均
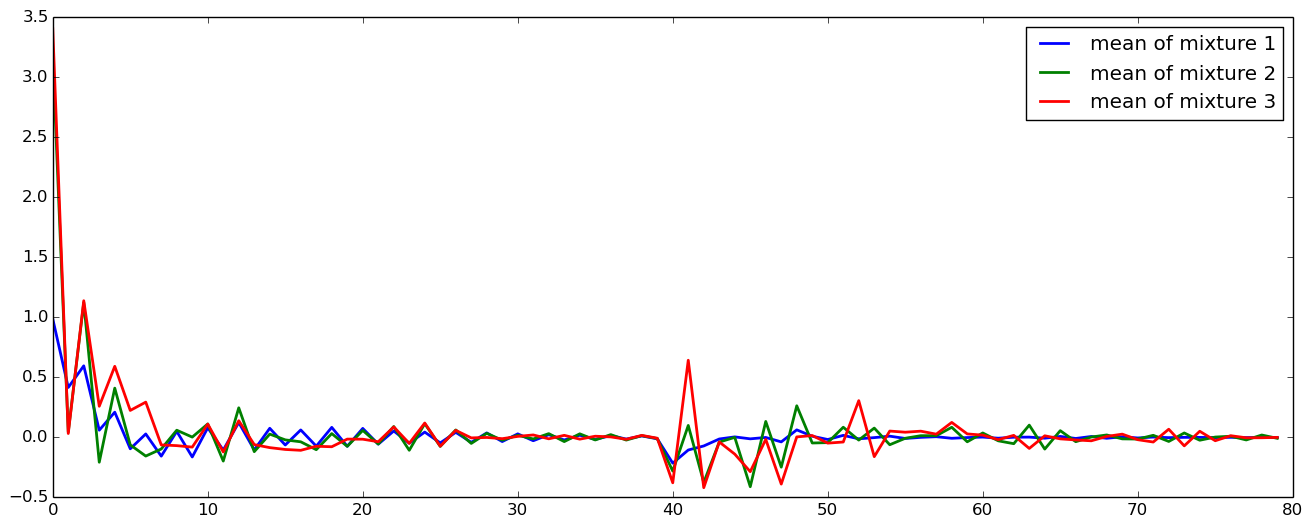
共分散
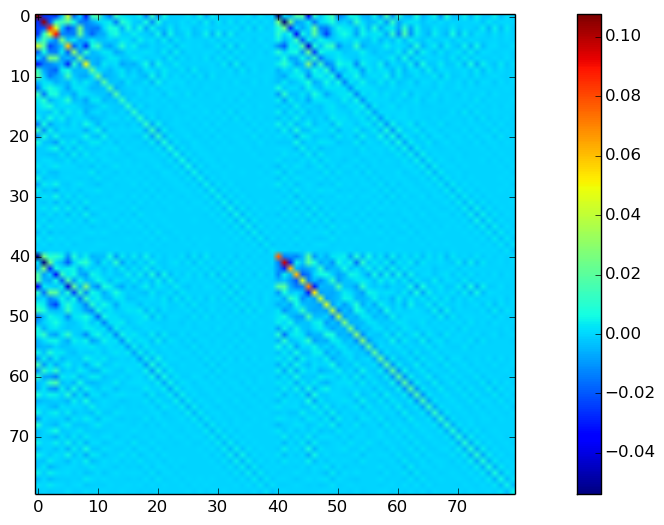
さっき学習したGMMとは、共分散はかなり形が違いますね。高次元成分でも、分散が比較的大きな値をとっているように見えます。形が異っているのは見てすぐにわかりますが、では具体的には何が異っているのか、それはなぜなのか、きちんと考えると面白そうですね。
5.2 MLSAフィルタによる声質変換
差分スペクトル補正に基づく声質変換では、WORLDを使って音声の分析合成を行うのではなく、生の音声波形を入力として、MLSAフィルタをかけるのみです。これは、 scripts/diffvc.jl を使うと簡単にできます。
julia diffvc.jl ~/data/cmu_arctic/cmu_us_clb_arctic/wav/arctic_a0028.wav clb_to_slt_gmm32_order40_diff.jld clb_to_slt_a0028_diff.wav --order 40
さて、結果を聞いてみましょう。
5.3 差分スペクトル補正に基づく声質変換結果
アイデアはシンプル、結果は良好、最高の手法ですね(べた褒め
おわりに
以上、長くなりましたが、統計的声質変換についてのチュートリアルはこれで終わります。誰の役に立つのか知らないけれど、役に立てば嬉しいです。トラジェクトリ変換やGVを考慮したバージョンなど、今回紹介していないものも実装しているので、詳しくはGithubのリポジトリをチェックしてください。バグをレポートしてくれたりすると、僕は喜びます。
参考
以前書いた声質変換に関する記事
論文
- [Toda 2007] T. Toda, A. W. Black, and K. Tokuda, “Voice conversion based on maximum likelihood estimation of spectral parameter trajectory,” IEEE Trans. Audio, Speech, Lang. Process, vol. 15, no. 8, pp. 2222–2235, Nov. 2007.
- [Kobayashi 2014] Kobayashi, Kazuhiro, et al. “Statistical Singing Voice Conversion with Direct Waveform Modification based on the Spectrum Differential.” Fifteenth Annual Conference of the International Speech Communication Association. 2014.
FAQ
前はpythonで書いてなかった?
はい、https://gist.github.com/r9y9/88bda659c97f46f42525 ですね。正確には、GMMの学習・変換処理はpythonで書いて、特徴抽出、パラレルデータの作成、波形合成はGo言語で書いていました。が、Goとpythonでデータのやりとり、Goとpythonをいったり来たりするのが面倒になってしまって、一つの言語に統一したいと思うようになりました。Goで機械学習は厳しいと感じていたので、pythonで書くかなぁと最初は思ったのですが、WORLDやSPTKなど、Cのライブラリをpythonから使うのが思いの他面倒だったので(SPTKのpythonラッパーは書きましたが)、Cやpythonとの連携がしやすく、スクリプト言語でありながらCに速度面で引けをとらないjuliaに興味があったので、juliaですべて完結するようにしました。かなり実験的な試みでしたが、今はかなり満足しています。juliaさいこー
新規性は?
ありません
Ryuichi Yamamoto
Engineer/Researcher
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.