Tacotron: Towards End-to-End Speech Synthesis / arXiv:1703.10135 [cs.CL]
Googleが2017年4月に発表したEnd-to-Endの音声合成モデル Tacotron: Towards End-to-End Speech Synthesis / arXiv:1703.10135 [cs.CL] に興味があったので、自分でも同様のモデルを実装して実験してみました。結果わかったことなどをまとめておこうと思います。
GoogleによるTacotronの音声サンプルは、 https://google.github.io/tacotron/ から聴けます。僕の実装による音声サンプルはこの記事の真ん中くらいから、あるいは Test Tacotron.ipynb | nbviewer1 から聴くことができます。
とても長い記事になってしまったので、結論のみ知りたい方は、一番最後まで飛ばしてください。最後の方のまとめセクションに、実験した上で僕が得た知見がまとまっています。
概要
論文のタイトルにもある通り、End-to-Endを目指しています。典型的な(複雑にあなりがちな)音声合成システムの構成要素である、
- 言語依存のテキスト処理フロントエンド
- 言語特徴量と音響特徴量のマッピング (HMMなりDNNなり)
- 波形合成のバックエンド
を一つのモデルで達成しようとする、attention付きseq2seqモデル を提案しています。ただし、Toward とあるように、完全にEnd-to-Endではなく、ネットワークは波形ではなく 振幅スペクトログラム を出力し、Griffin limの方法によって位相を復元し、逆短時間フーリエ変換をすることによって、最終的な波形を得ます。根本にあるアイデア自体はシンプルですが、そのようなEnd-to-Endに近いモデルで高品質な音声合成を実現するのは困難であるため、論文では学習を上手くいくようするためのいくつかのテクニックを提案する、といった主張です。以下にいくつかピックアップします。
- エンコーダに CBFG (1-D convolution bank + highway network + bidirectional GRU) というモジュールを使う
- デコーダの出力をスペクトログラムではなく(より低次元の)メル周波数スペクトログラム にする。スペクトログラムはアライメントを学習するには冗長なため。
- スペクトログラムは、メル周波数スペクトログラムに対して CBFG を通して得る
その他、BatchNormalizationを入れたり、Dropoutを入れたり、GRUをスタックしたり、と色々ありますが、正直なところ、どれがどのくらい効果があるのかはわかっていません(調べるには、途方もない時間がかかります)が、論文の主張によると、これらが有効なようです。
既存実装
Googleは実装を公開していませんが、オープンソース実装がいくつかあります。
- https://github.com/Kyubyong/tacotron
- https://github.com/barronalex/Tacotron
- https://github.com/keithito/tacotron
自分で実装する前に、上記をすべてを簡単に試したり、生成される音声サンプルを比較した上で、僕は keithito/tacotron が一番良いように思いました。最も良いと思った点は、keithito さんは、LJ Speech Dataset という単一話者の英語読み上げ音声 約24時間のデータセットを構築 し、それを public domainで公開 していることです。このデータセットは貴重です。デモ音声サンプルは、そのデータセットを使った結果でもあり、他と比べてとても高品質に感じました。自分でも試してみて、1時間程度で英語らしき音声が生成できるようになったのと、さらに数時間でアライメントも学習されることを確認しました。
なお、上記3つすべてで学習スクリプトを回して音声サンプルを得る、程度のことは試しましたが、僕がコードレベルで読んだのは keithito/tacotron のみです。読んだコードは、TensorFlowに詳しくない僕でも読めるもので、とても構造化されていて読みやすかったです。
自前実装
勉強も兼ねて、PyTorchでスクラッチから書きました。その結果が https://github.com/r9y9/tacotron_pytorch です。
先にいくつか結論を書いておくと、
- 音の品質は、keithito/tacotron の方が良く感じました(同じモデルの実装を心がけたのに…つらい…)。ただ、データセットの音声には残響が乗っていて、生成された音声が元音声に近いのかというのは、僕には判断がつきにくいです。記事の後半に比較できるようにサンプルを貼っておきますので、気になる方はチェックしてみてください
- keithito/tacotron では長い入力だと合成に失敗する一方で2、僕の実装では比較的長くてもある程度合成できるようです。なぜのかを突き詰めるには、TensorFlowのseq2seq APIの コード (APIは抽象化されすぎていてdocstringからではよくわからないので…) を読みとく必要があるかなと思っています(やっていませんすいません
実験
基本的には keithito/tacotron の学習スクリプトと同じで、LJ Speech Dataset を使って学習させました。テキスト処理、音声処理 (Griffin lim等) には既存のコードをそのまま使用し、モデル部分のみ自分で置き換えました。実験では、
- attention付きseq2seqの肝である、アライメントがどのように学習されていくのか
- 学習が進むにつれて、生成される音声はどのように変わっていくのか
- 学習されたモデルは、汎化性能はどの程度なのか(未知文章、長い文章、スペルミスに対してパフォーマンスはどう変わるのか、等)
を探っていきました。
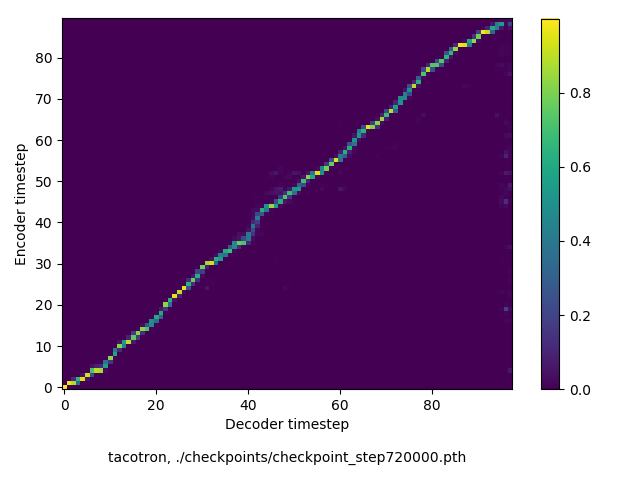
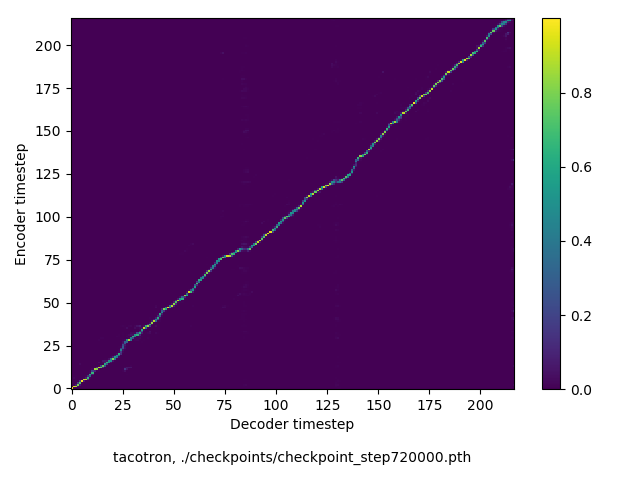
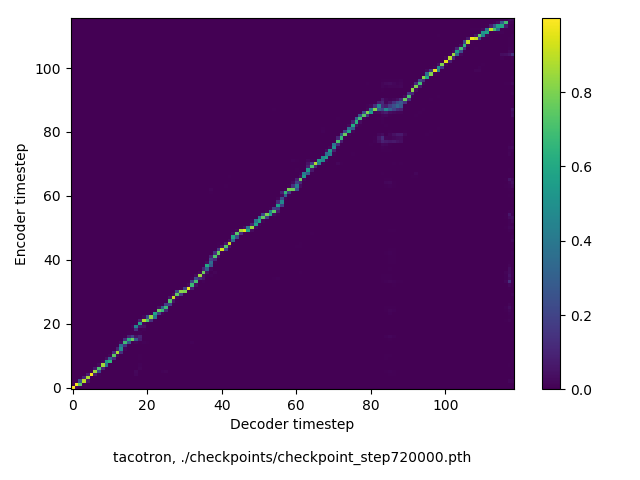
アライメントの学習過程の可視化
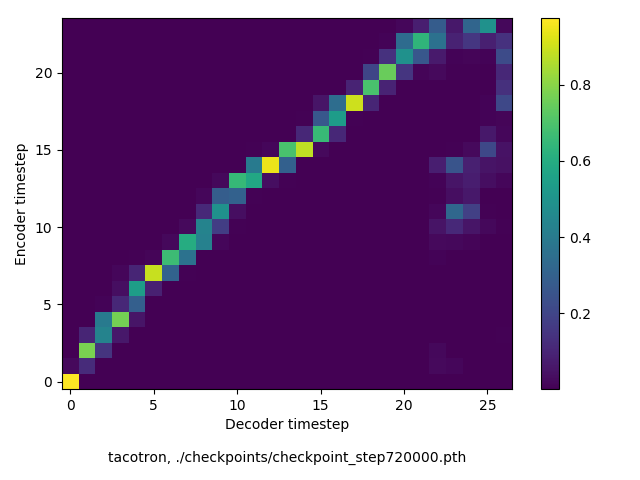
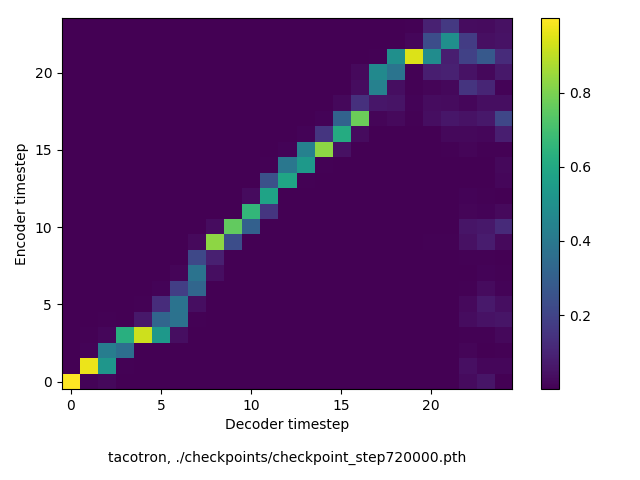
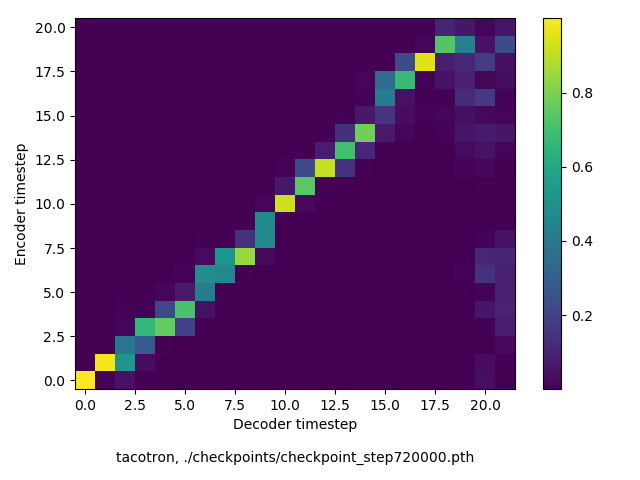
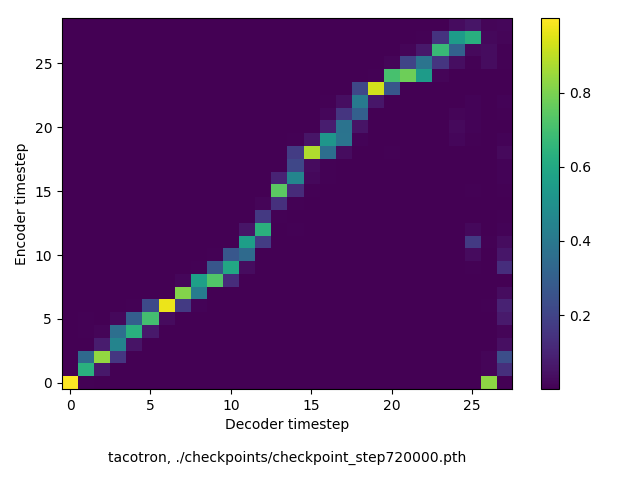
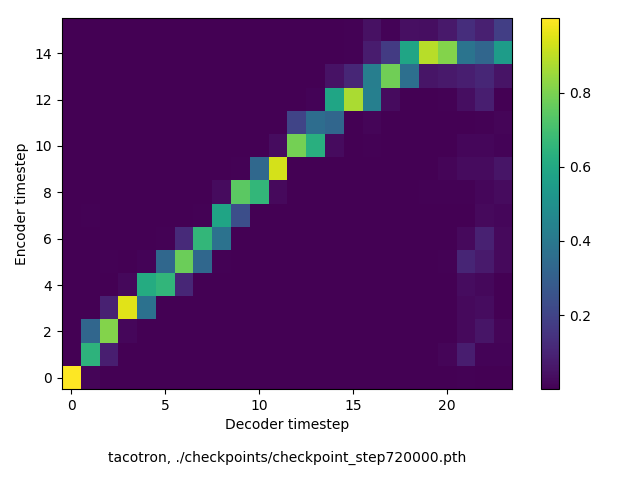
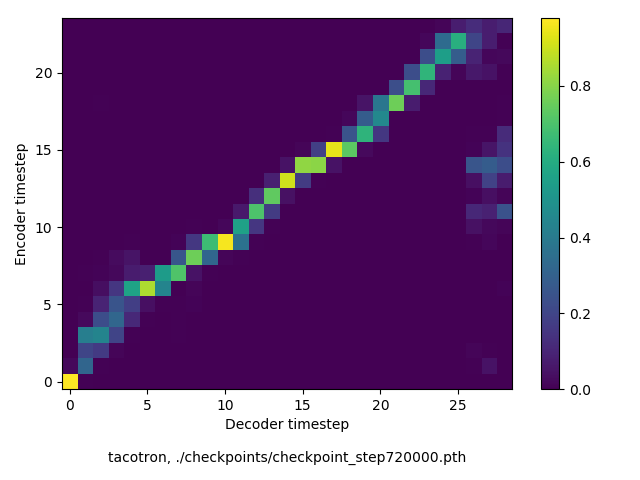
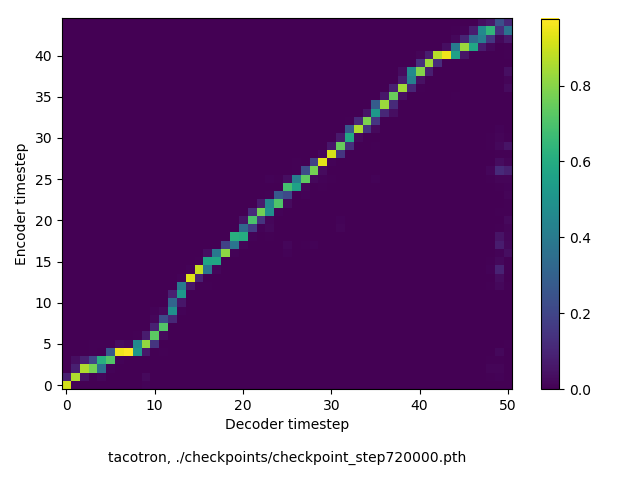
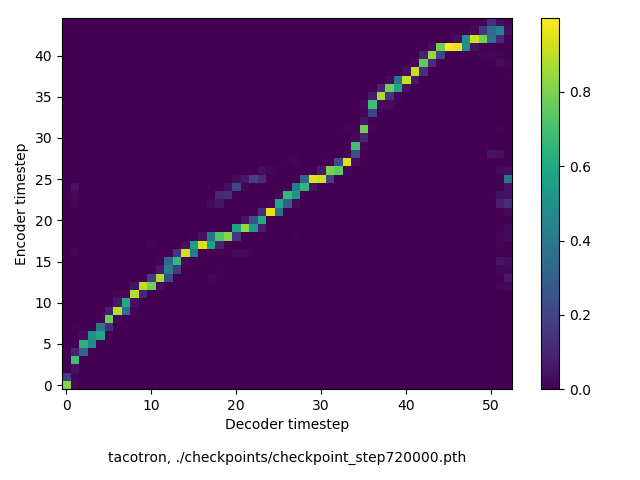
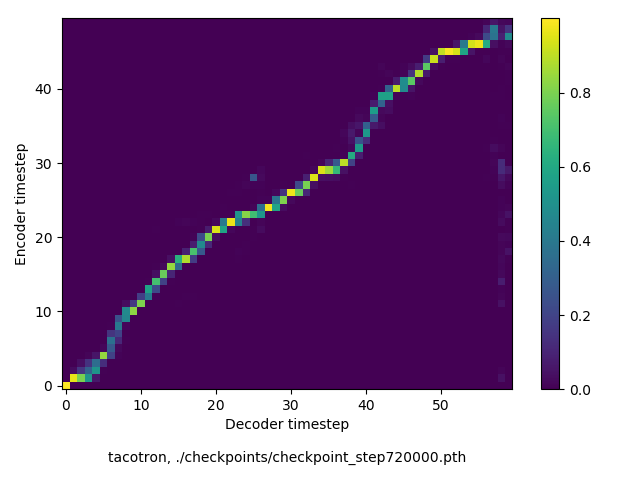
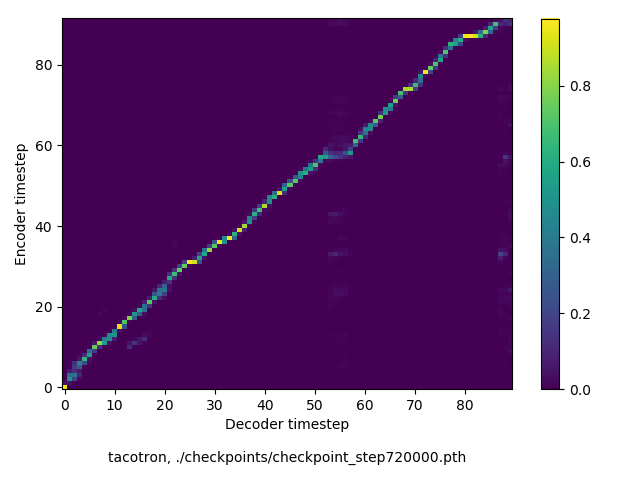
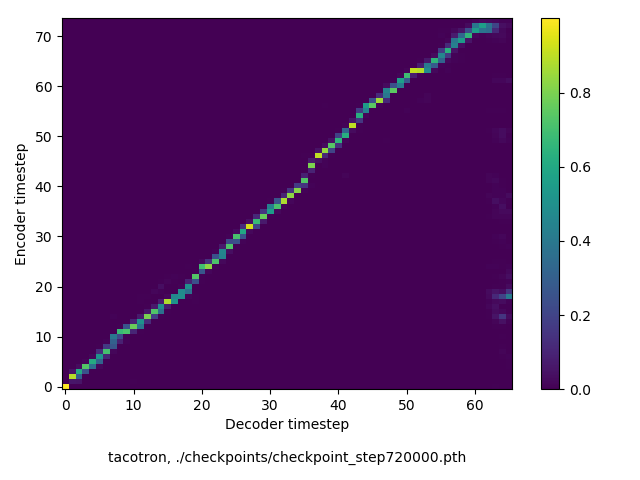
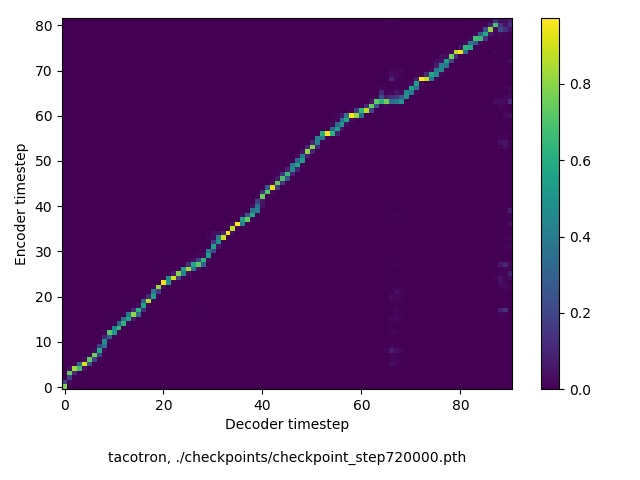
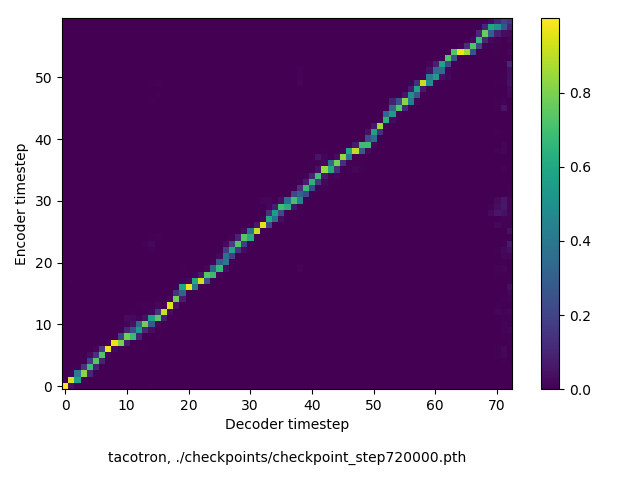
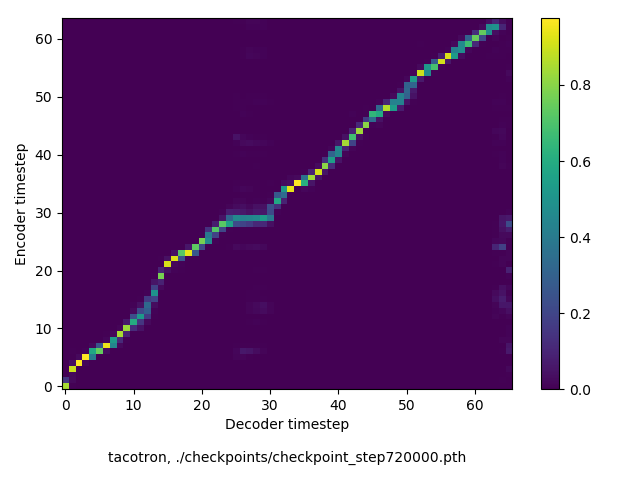
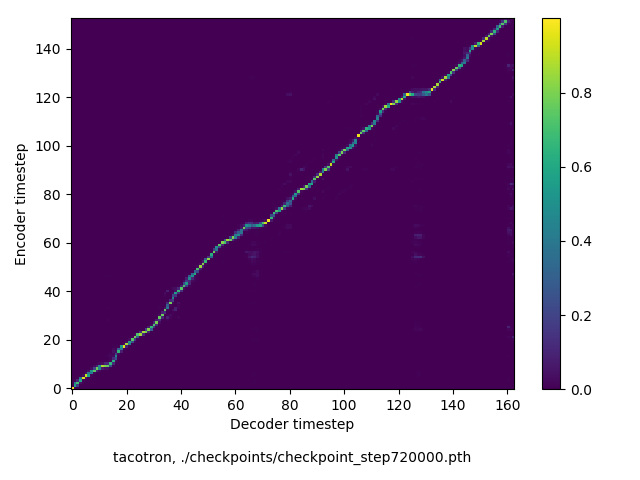
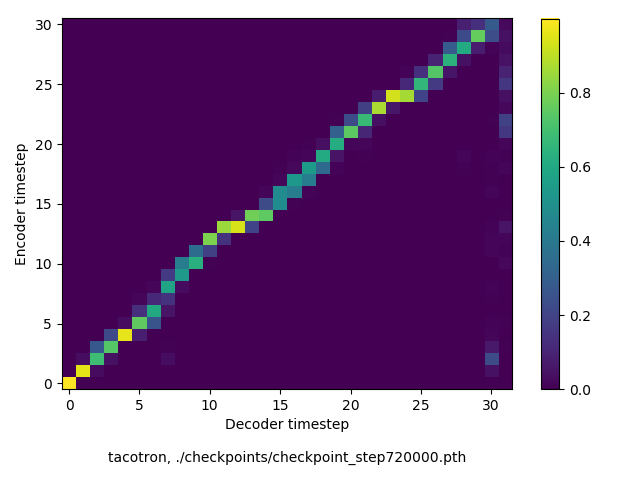
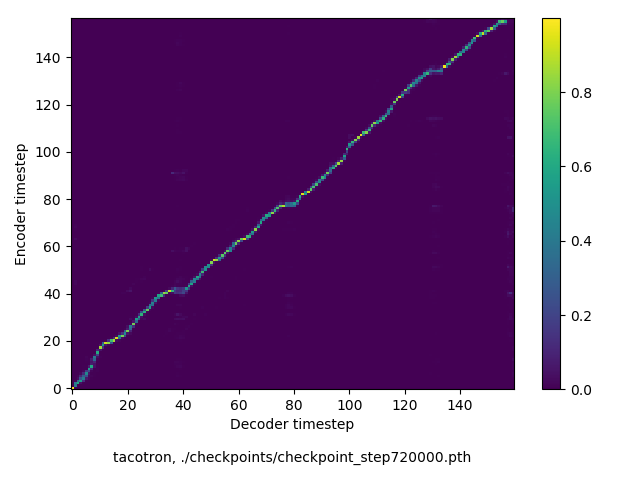
通常のseq2seqは、エンコーダRNNによって得た最後のタイムステップにおける隠れ層の状態を、デコーダのRNNの初期状態として渡します。一方attentiont付きのseq2seqモデルでは、デコーダRNNは各タイムステップで、エンコーダRNNの各タイムステップにおける隠れ層の状態を重みづけて使用し、その重みも学習します。attention付きのseq2seqでは、アライメントがきちんと(曖昧な表現ですが)学習されているかを可視化してチェックするのが、学習がきちんと進んでいるのか確認するのに便利です。
以下に、47000 step (epochではありません。僕の計算環境 GTX 1080Ti で半日かからないくらい) iterationしたときのアライメント結果と、47000 stepの時点での予測された音声サンプルを示します。なお、gifにおける各画像は、データセットをランダムにサンプルした際のアライメントであり、ある同じ音声に対するアライメントではありません。Tacotron論文には、Bahdanau Attentionを使用したとありますが、keithito/tacotron #24 Try Monotonic Attention によると、Tacotron論文の第一著者は新しいバージョンのTacotronでは Monotonic attentionを使用しているらしいということから、Monotonic Attentionでも試してみました。あとでわかったのですが、長文(200文字、数文とか)を合成しようとすると途中でアライメントがスキップすることが多々見受けられたので、そういった場合に、monotonicという制約が上手く働くのだと思います。
以下の順でgifを貼ります。
- keithito/tacotron, Bahdanau attention
- keithito/tacotron, Bahdanau-style monotonic attention
- r9y9/tacotron_pytorch, Bahdanau attention
keithito: Bahdanau Attention
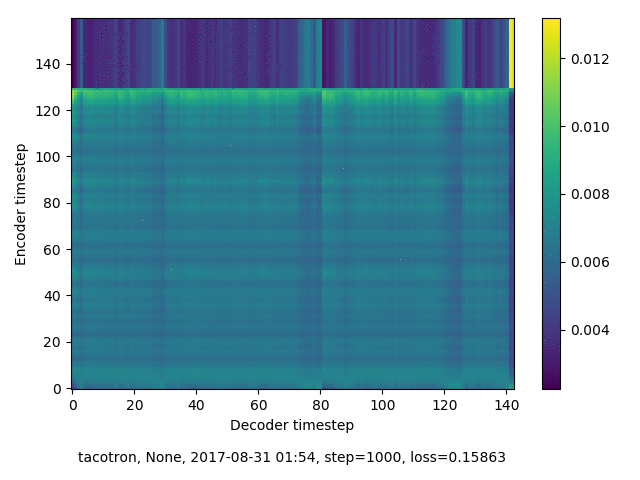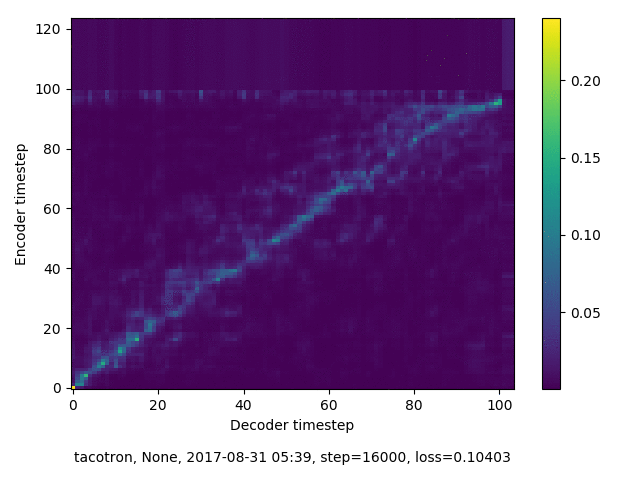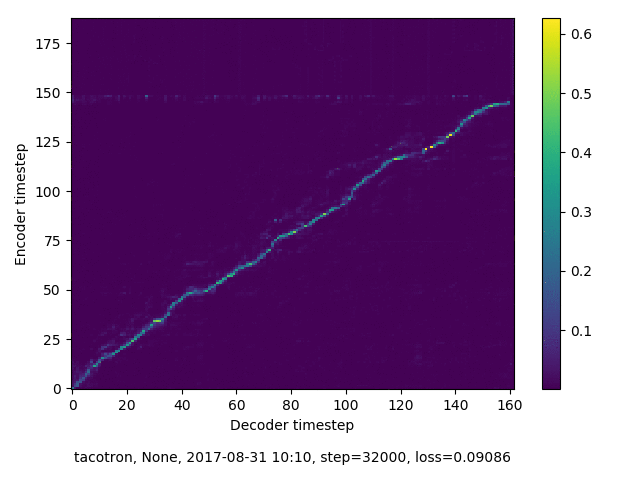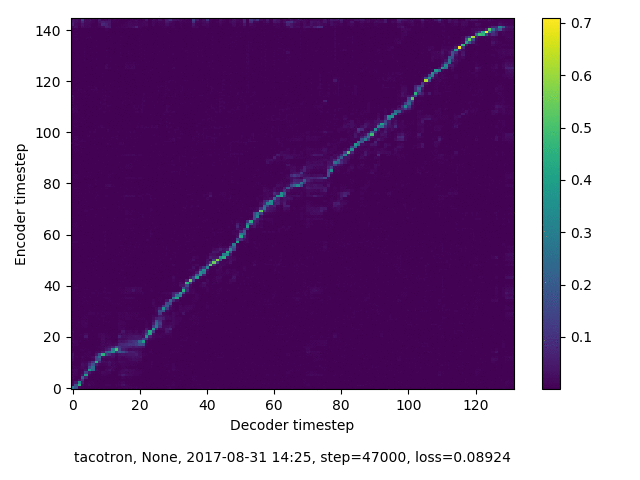
keithito: (Bahdanau-style) Monotonic Attention
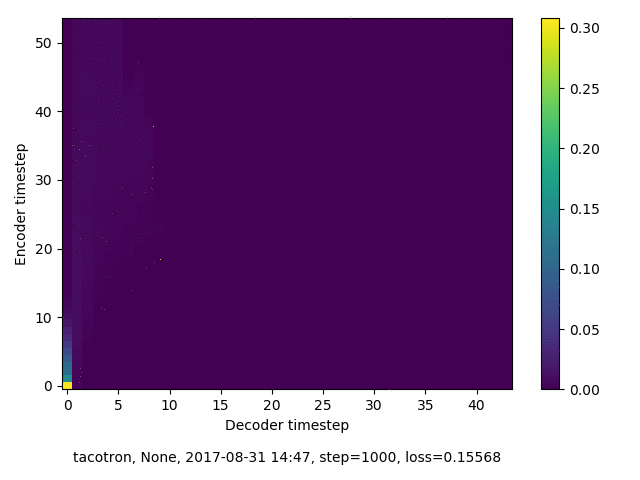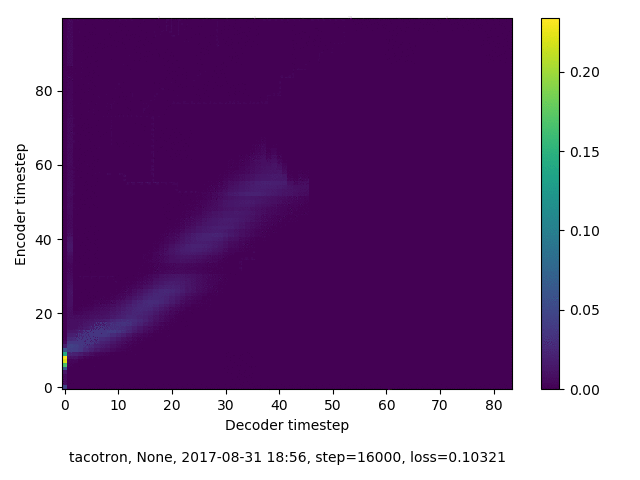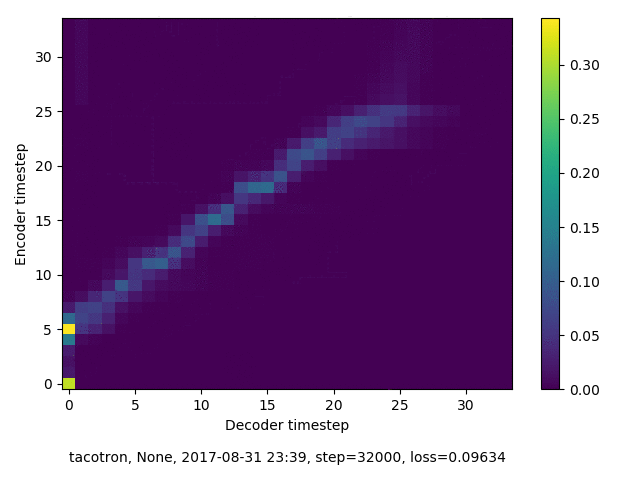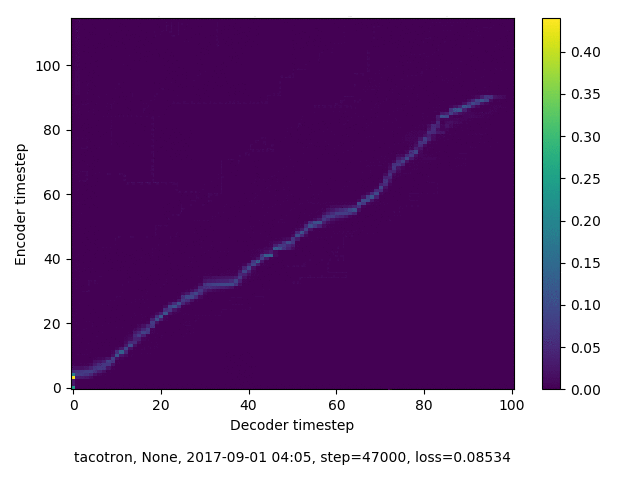
自前実装: Bahdanau Attention
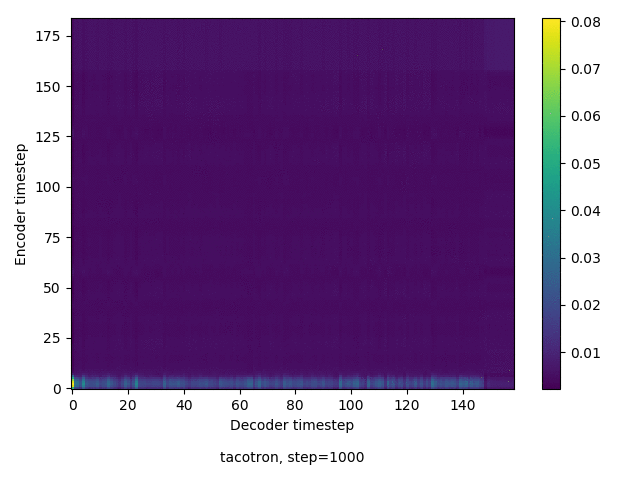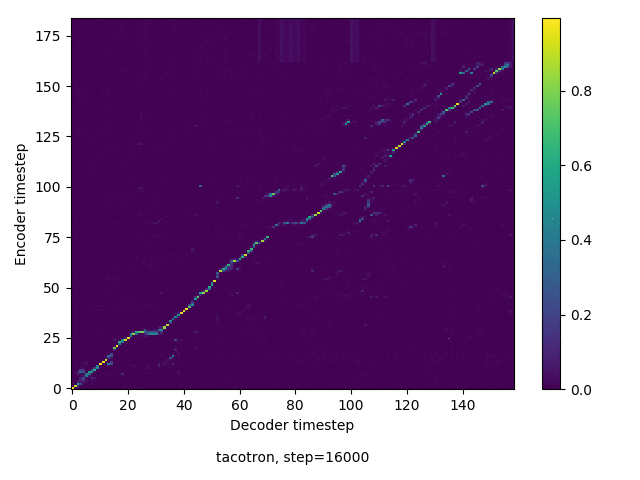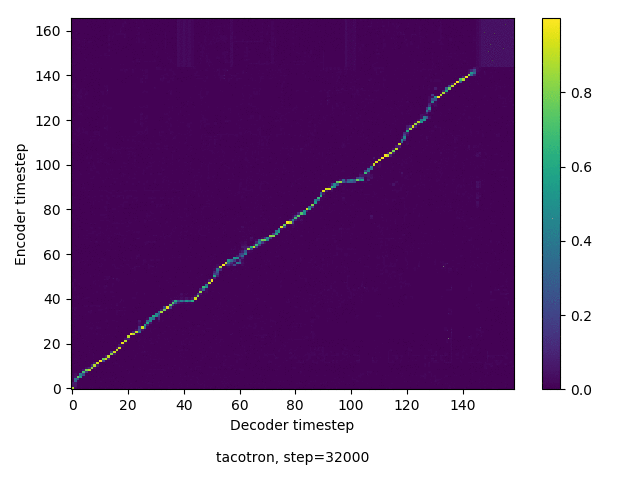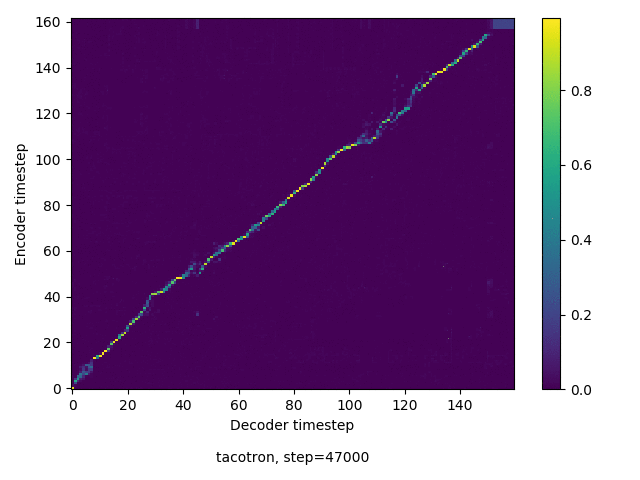
Monotonicかどうかで比較すると、Monotonic attentionの方がアライメントがかなり安定しているように見えます。しかし、Githubのスレッドにあった音声サンプルを聴くと、音質的な意味では大きな違いがないように思ったのと、収束速度(簡単に試したところ、アライメントがまともになりだすstepは20000くらいで、ほぼ同じでした)も同じに思えました。一方で自前実装は、アライメントがまともになるstepが10000くらいとやや早く、またシャープに見えます。
音声サンプルの方ですが、既存実装は両者ともそれなりにまともです。一方自前実装では、まだかなりノイジーです。できるだけtf実装と同じようにつくり、実験条件も同じにしたつもりですが、何か間違っているかもしれません。が、イテレーションを十分に回すと、一応音声はそれなりに出るようになります。
音声サンプルに関する注意点としては、これはデコードの際に教師データを使っているので、この時点でのモデル使って、同等の音質の音声を生成できるとは限りません。学習時には、デコーダの各タイムステップで教師データのスペクトログラム(正確には、デコーダの出力はメル周波数スペクトログラム)を入力とする一方で、評価時には、デコーダ自身が出力したスペクトログラムを次のタイムステップの入力に用います。評価時には、一度変なスペクトログラムを出力してしまったら、エラーが蓄積していってどんどん変な出力をするようになってしまうことは想像に難しくないと思います。seq2seqモデルのデコードにはビームサーチが代表的なものとしてありますが、Tacotronでは単純にgreedy decodingをします。
学習が進むにつれて、生成される音声はどのように変わっていくのか
さて、ここからは自前実装のみでの実験結果です。約10日、70万step程度学習させましたので、5000, 10000, 50000, そのあとは10万から10万ステップごとに70万ステップまでそれぞれで音声を生成して、どのようになっているのかを見ていきます。
例文1
Hi, my name is Tacotron. I’m still learning a lot from data.
(56 chars, 14 words)
step 5000
step 10000
step 50000
step 100000
step 200000
step 300000
step 400000
step 500000
step 600000
step 700000
だいたい20万ステップ(学習二日くらい)から、まともな音声になっているように感じます。細かいところでは、Hi, Tacotron という部分が少し発音しにくそうです。データセットにはこのような話し言葉のようなものが少ないのと、Tacotron という単語が英語らしさ的な意味で怪しいから(造語ですよね、たぶん)と考えられます。
例文2
https://en.wikipedia.org/wiki/Python_(programming_language) より引用:
Python is a widely used high-level programming language for general-purpose programming, created by Guido van Rossum and first released in 1991.
(144 chars, 23 words)
step 5000
step 10000
step 50000
step 100000
step 200000
step 300000
step 400000
step 500000
step 600000
step 700000
だいたい20万ステップから、まともな音声になっているように思います。
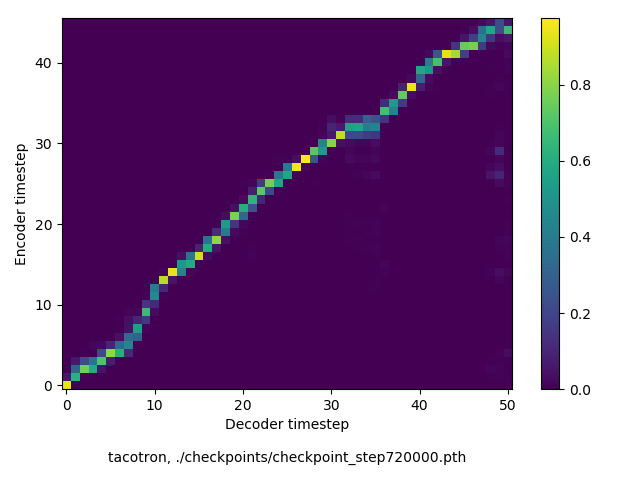
モデルの汎化性能について調査
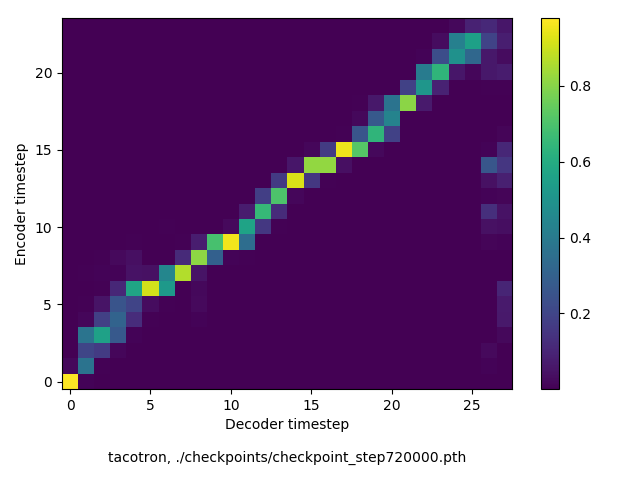
以下、72万ステップ(一週間くらい)学習させたモデルを使って、いろんな入力でテストした結果です。音声と合わせてアライメントも貼っておきます。
適当な未知入力
データセットには存在しない文章を使ってテストしてみました。ところどころ(非ネイティブの僕にでも)不自然だと感じるところが見られますが、とはいえまぁまぁいい感じではないでしょうか。(google translateで同じ文章を合成してみて比べても、そんなに悪くない気がしました)
https://en.wikipedia.org/wiki/PyPy より:
PyPy is an alternate implementation of the Python programming language written in Python.
(89 chars, 14 words)
https://en.wikipedia.org/wiki/NumPy より:
NumPy is a library for the Python programming language, adding support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays.
(215 chars, 35 words)
Numba gives you the power to speed up your applications with high performance functions written directly in Python.
(115 chars, 19 words)
スペルミス
スペルミスがある場合に、合成結果はどうなるのか、といったテストです。Googleのデモにあるように、ある程度ロバスト(少なくとも全体が破綻するといったことはない)のように思いました。
Thisss isrealy awhsome.
(23 chars, 4 words)
This is really awesome.
(23 chars, 5 words)
I cannnnnot believe it.
(23 chars, 5 words)
I cannot believe it.
(20 chars, 6 words)
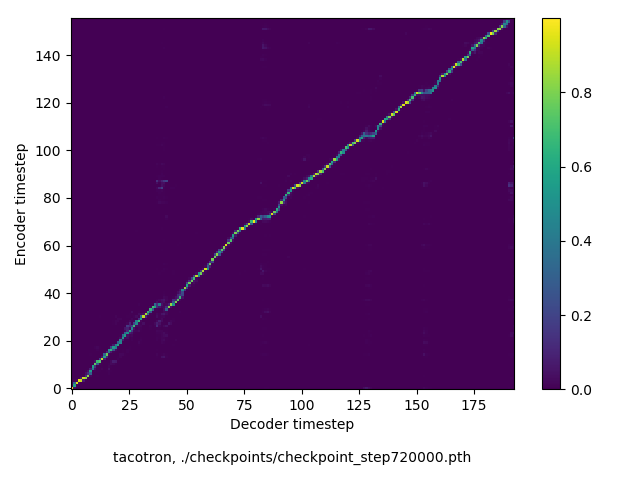
中〜少し長めの文章
だいたい250文字を越えたくらいで、単語がスキップされるなどの現象が多く確認されました。データセットは基本的に短い文章の集まりなのが理由に思います。前述の通り、monotonic attentionを使えば、原理的にはスキップされにくくなると思います。
https://arxiv.org/abs/1703.10135 より引用:
A text-to-speech synthesis system typically consists of multiple stages, such as a text analysis frontend, an acoustic model and an audio synthesis module.
(155 chars, 26 words)
https://americanliterature.com/childrens-stories/little-red-riding-hood より引用:
Once upon a time there was a dear little girl who was loved by every one who looked at her, but most of all by her grandmother, and there was nothing that she would not have given to the child.
(193 chars, 43 words)
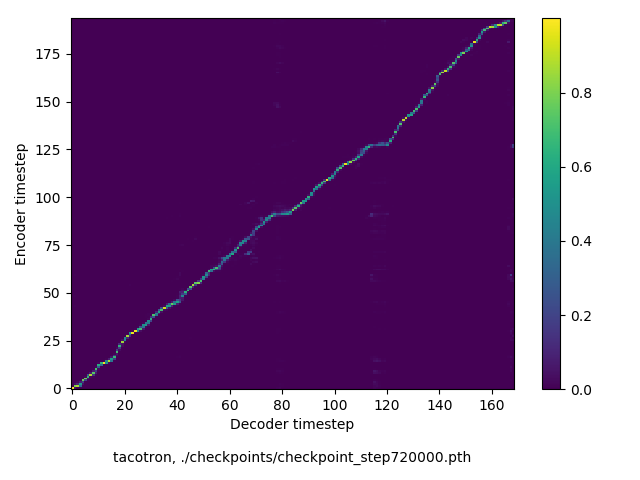
https://arxiv.org/abs/1703.10135 より引用:
A text-to-speech synthesis system typically consists of multiple stages, such as a text analysis frontend, an acoustic model and an audio synthesis module. Building these components often requires extensive domain expertise and may contain brittle design choices.
(263 chars, 41 words)
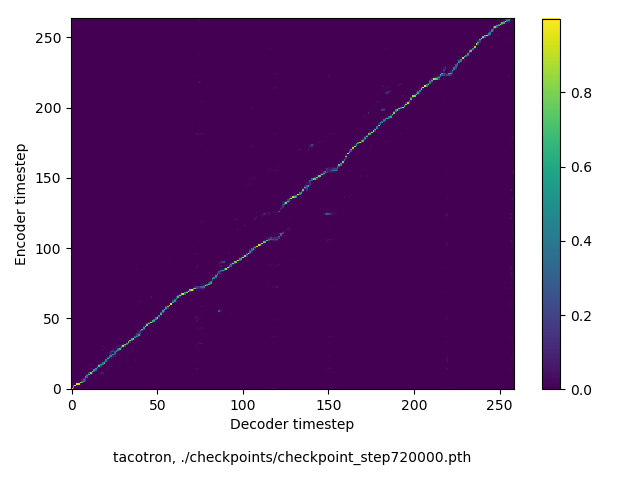
https://americanliterature.com/childrens-stories/little-red-riding-hood より引用:
Once upon a time there was a dear little girl who was loved by every one who looked at her, but most of all by her grandmother, and there was nothing that she would not have given to the child. Once she gave her a little cap of red velvet, which suited her so well that she would never wear anything else. So she was always called Little Red Riding Hood.
(354 chars, 77 words)

Googleのデモと比較
https://google.github.io/tacotron/ の音声サンプルと同じ文章で試します。大文字小文字の区別は今回学習したモデルでは区別しないので、一部例文は除いています。いくつか気づいたことを挙げておくと、
- He has read the whole thing. / He reads book. のように、readの読みが動詞の活用形によって変わるような場合なのですが、上手く行くときといかないときがありました。イテレーションを進めていく上で、ロスは下がり続ける一方で、きちんと区別して発音できるようになったりできなくなってしまったり、というのを繰り返していました。
?が文末につくことで、イントネーションが変わってくれることを期待しましたが、データセット中に?が少なすぎたのか、あまりうまくいかなかったように思います。- out-of-domainの文章にもロバストのように思いましたが、二個目の例文のような、(複雑な?)専門用語の発音は、厳しい感じがしました。
Generative adversarial network or variational auto-encoder.
(59 chars, 7 words)
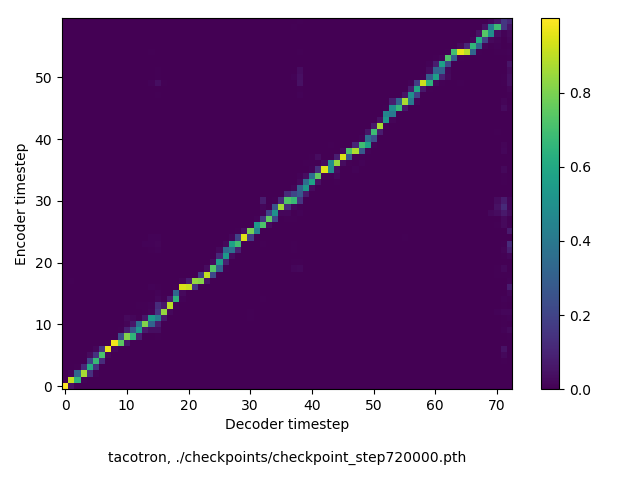
Basilar membrane and otolaryngology are not auto-correlations.
(62 chars, 8 words)
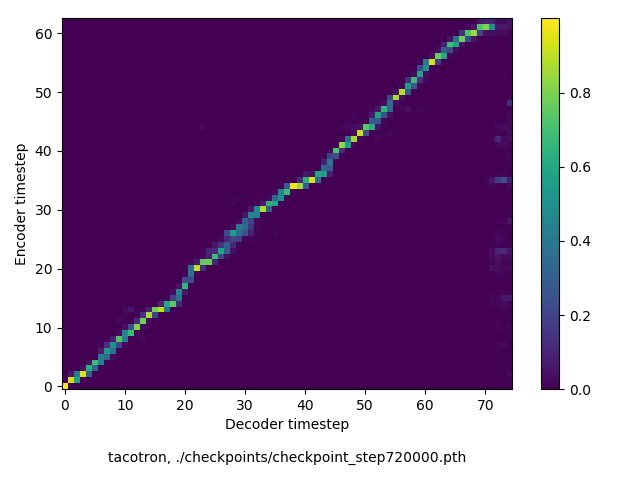
He has read the whole thing.
(28 chars, 7 words)
He reads books.
(15 chars, 4 words)
Thisss isrealy awhsome.
(23 chars, 4 words)
This is your personal assistant, Google Home.
(45 chars, 9 words)
This is your personal assistant Google Home.
(44 chars, 8 words)
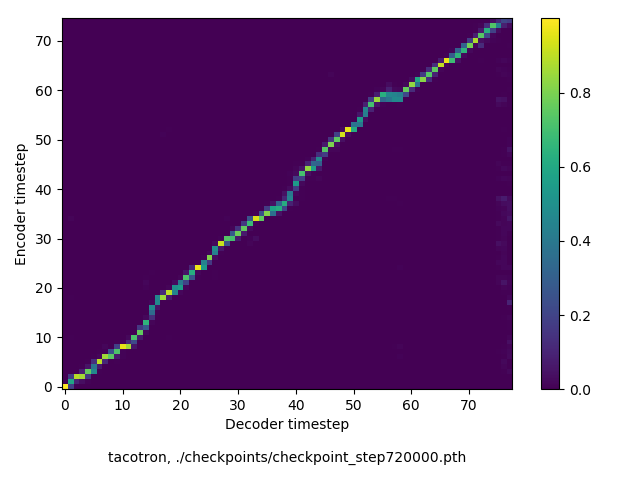
The quick brown fox jumps over the lazy dog.
(44 chars, 10 words)
Does the quick brown fox jump over the lazy dog?
(51 chars, 11 words)
keithito/tacotron との比較
https://keithito.github.io/audio-samples/ の audio samples で使われている文章に対するテストです。比較しやすいように、比較対象の音声も合わせて貼っておきます。自前実装で生成したもの、keithito/tacotron で生成したもの、の順です。
Scientists at the CERN laboratory say they have discovered a new particle.
(74 chars, 13 words)
There’s a way to measure the acute emotional intelligence that has never gone out of style.
(91 chars, 18 words)
President Trump met with other leaders at the Group of 20 conference.
(69 chars, 13 words)
The Senate’s bill to repeal and replace the Affordable Care Act is now imperiled.
(81 chars, 16 words)
Generative adversarial network or variational auto-encoder.
(59 chars, 7 words)
The buses aren’t the problem, they actually provide a solution.
(63 chars, 13 words)
Ground truth との比較
最後に、元のデータセットとの比較です。学習データからサンプルを取ってきて比較します。自前実装で生成したもの、ground truthの順に貼ります。
Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition.
(152 chars, 30 words)
in being comparatively modern.
(30 chars, 5 words)
For although the Chinese took impressions from wood blocks engraved in relief for centuries before the woodcutters of the Netherlands, by a similar process.
(156 chars, 26 words)
produced the block books, which were the immediate predecessors of the true printed book,
(89 chars, 16 words)
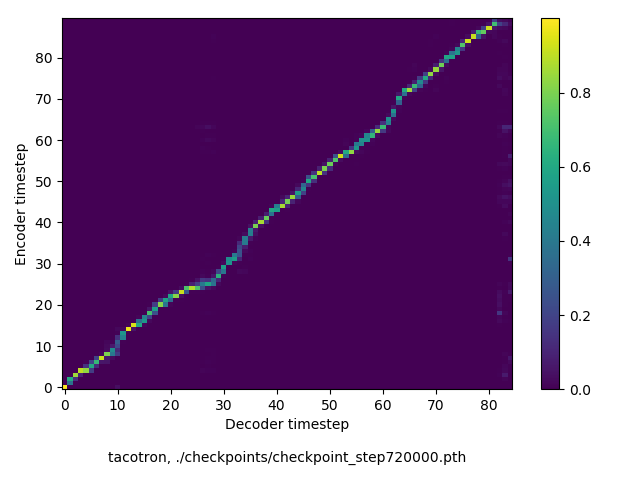
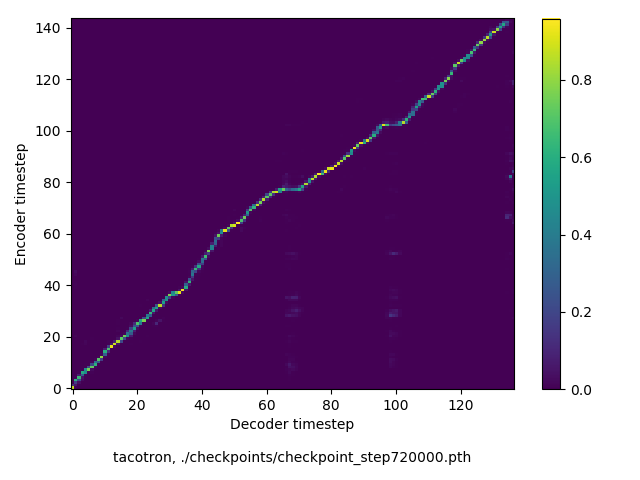
the invention of movable metal letters in the middle of the fifteenth century may justly be considered as the invention of the art of printing.
(143 chars, 26 words)
元音声があまり良いクリーンな音声ではないとはいえ、まー元音声とは大きな違いがありますねー、、厳しいです。スペクトログラムを見ている限りでは(貼ってないですが、すいません)、明らかに高周波数成分の予測が上手く言っていないことはわかっています。ナイーブなアイデアではありますが、GANを導入すると良くなるのではないかと思っています。
おまけ:生成する度に変わる音声
実験する過程で副次的に得られた結果ではあるのですが、テスト時に一部dropoutを有効にしていると3、生成する度に音声が異なる(韻律が微妙に変わる)、といった現象を経験しています。以下、前に検証した際の実験ノートのリンクを貼っておきます。
http://nbviewer.jupyter.org/gist/r9y9/fe1945b73cd5b98e97c61410fe26a851#Try-same-input-multiple-times
まとめ & 感想など
- Tacotronを実装しました https://github.com/r9y9/tacotron_pytorch
- 24時間のデータセットに対して、20万ステップ程度(数日くらい)学習させたらそれなりにまともな音声が生成できるようになりました。70万ステップ(一週間と少しくらい)学習させましたが、ずっとロスは下がり続ける一方で、50万くらいからはあまり大きな品質改善は見られなかったように思います。
- Googleの論文と(ほぼ4)同じように実装したつもりですが、品質はそこまで高くならなかったように思います。End-to-end では、 データの量と品質 がかなり重要なので、それが主な原因だと思っています。(僕の実装に、多少バグがあるかもしれませんが、、、
- EOS (End-of-sentence) では、理想的には要素がすべて0のスペクトログラムが出力されるはずなのですが、実際にはやはりそうもいかないので、判定には以下のようなしきい値処理を用いました。ここで貼った音声は全部この仕組みで動いており、単純ですがそれなりに上手く機能しているようです。
def is_end_of_frames(output, eps=0.2):
return (output.data <= eps).all()
- 論文からは非自明な点の一つとして、エンコーダの出力のうち、入力のゼロ詰めした部分をマスキングするかどうか、といった点があります。これは、既存実装によってもまちまちで、例えば keithito/tacotron ではマスキングしていませんが、barronalex/Tacotron ではマスクしています。僕はマスクする場合としない場合と両方試したのですが(ここに貼った結果は、マスクしていない場合のものです)、マスクしないほうが若干良くなったような気もします。理想的にはマスクするべきだと思ったのですが、実際に試したところどちらかが圧倒的に悪いという結果ではありませんでした。発見した大きな違いの一つは、マスクなしの場合はアテンションは大まかにmonotonicになる一方で、マスクありの場合は、無音区間ではエンコーダ出力の冒頭にアテンションの重みが大きくなる(ので、monotonicではない)、と言ったことがありました。マスクありの音声サンプル、アライメントの可視化は、(少し古いですが)ここ にあります。参考までに、Tensorflowでエンコーダの出力マスクする場合は、
memory_sequence_lengthを指定します https://www.tensorflow.org/api_docs/python/tf/contrib/seq2seq/BahdanauAttention - 日本語でやったり、multi-speaker でやったりしたかったのですが、とにかく実験に時間がかかるので、今のところ僕の中では優先度が低めになってしまいました。時間と計算資源に余裕があれば、やりたいのですが…
- 日本語でやるには、英語と同じようにはいきません。というのも、char-levelで考えた際に、語彙が大きすぎるので。やるならば、十分大きな日本語テキストコーパスからembeddingを別途学習して(Tacotronでは、モデル自体にembeddingが入っています)、その他の部分を音声つきコーパスで学習する、といった方法が良いかなと思います。CSJコーパスは結構向いているんじゃないかと思っています。
- multi-speakerモデルを考える場合、どこにembeddingを差し込むのか、といったことが重要になってきますが、keithito/tacotron/issues/18 や keithito/tacotron/issues/24 に少し議論があるので、興味のある人は見てみるとよいかもしれません。DeepVoiceの論文も参考になるかと思います
- 最新のTensorFlowでは、griffin lim や stft(GPUで走る、勾配が求められる)が実装されているので、tacotronモデルを少し拡張して、サンプルレベルでロスを考える、といったことが簡単に試せると思います(ある意味WaveNetです)。ただし、ものすごく計算リソースを必要とするのが容易に想像がつくので、僕はやっていません。GPU落ちてこないかな、、、
- Tacotronの拡張として、speaker embedding以外にも、いろんな潜在変数を埋め込んでみると、楽しそうに思いました。例えば話速、感情とか。
- TensorFlowのseq2seqあたりのドキュメント/コードをよく読んでいたのですが、APIが抽象化されすぎていてつらいなと思いました。例えばAttentionWrapper、コードを読まずに挙動を理解するのは無理なのではと思いました https://github.com/r9y9/tacotron_pytorch/issues/2#issuecomment-334255759
- keithito/tacotron は本当によく書かれているなと思ったので、TensorFlowに長けている方には、おすすめです
- 僕の実装では、バッチサイズ32でGPUメモリ5GB程度しか食わないので、Tacotronは比較的軽いモデルなのだなーと思いました。物体検出で有名な single shot multibox detector (通称SSD) なんかは、バッチサイズ16とかでも平気で12GBとか使ってくるので(一年近く前の経験ですが)、無限にGPUリソースがほしくなってきます
- これが僕にとって、はじめてまともにseq2seqを実装した経験でした。色々勉強したのですが、Attention mechanism に関しては、 http://colinraffel.com/blog/online-and-linear-time-attention-by-enforcing-monotonic-alignments.html がとても参考になりました。あとで知ったのですが、monotonic attentionの著者は僕が昔から使っている音楽信号処理のライブラリ librosa のコミッタでした(僕も弱小コミッタの一人)。とても便利で、よくテストされているので、おすすめです。オープンソースのTacotron実装でも、音声処理にも使われています
おわりに
End-to-End 音声合成は、言語処理のフロントエンドを(最低限の前処理を除き)必要としないという素晴らしさがあります。SampleRNN、Char2wavと他にも色々ありますが、今後もっと発展していくのではないかと思っています。おしまい。
参考
-
URLには現時点のgitのコミットハッシュが入っています。最新版は、 https://github.com/r9y9/tacotron_pytorch から直接辿ってください。 ↩︎
-
https://github.com/keithito/tacotron/pull/43#issuecomment-332068107 ↩︎
-
dropoutを切ってしまうと、アライメントが死んでしまうというバグ?に苦しんでおり…未だ原因を突き止められていません ↩︎
-
たとえばロスはちょっと違って、高周波数帯域に比べて低周波数帯域の重みを少し大きくしていたりしています。これは既存のtf実装に従いました。 ↩︎
Ryuichi Yamamoto
Engineer/Researcher
I am a engineer/researcher passionate about speech synthesis. I love to write code and enjoy open-source collaboration on GitHub. Please feel free to reach out on Twitter and GitHub.